 方案咨询
方案咨询


























 Tempo大数据分析平台
Tempo大数据分析平台 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo数据资产管理平台
Tempo数据资产管理平台 Tempo主数据管理平台
Tempo主数据管理平台

服务热线
400-608-2558
咨询热线
029-88696198

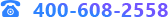

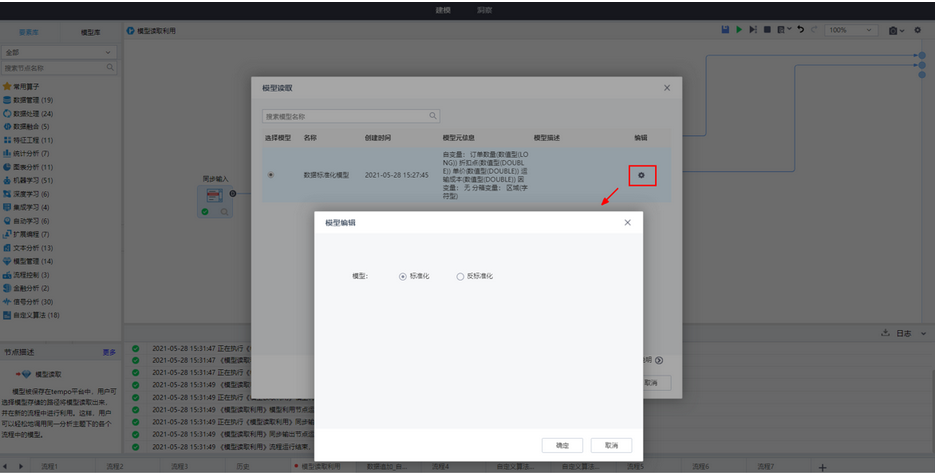
1.数据标准化输出的模型支持在模型读取中选择利用标准化或反标准化模型;
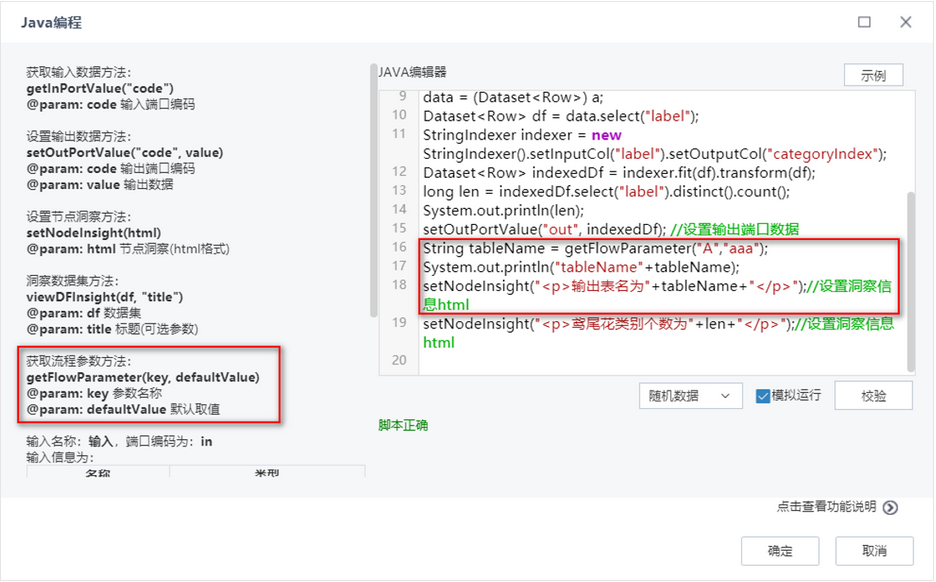
2.Java/Scala扩展编程使用流程参数机制优化,将流程参数通过函数的方式进行调用;
3.提交任务,流程资源使用情况监控,流程日志展示授权资源总量及剩余资源;
4.Linux/Windows对当前提交python任务增加资源设置机制(内存和CPU),避免影响其他任务;
5.输入查询分析器支持视图;
6.系统配置添加文件上传大小配置项;
7.查询生成器节点的汇总过滤实现一个计算列匹配另一个计算列过滤;
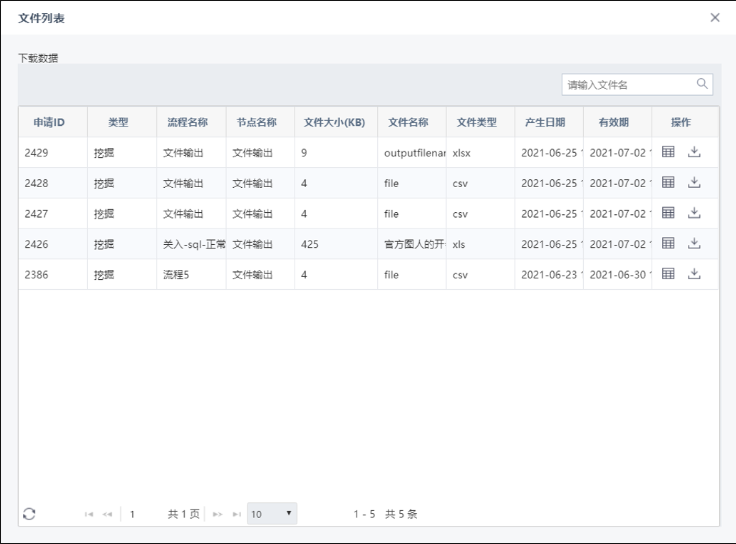
8. 文件列表新增“节点名称”、“文件大小”,“应用名称”改为“流程名称”,“申请日期”修改为“产生日期”,“截止日期”修改为“有效期”。
数据源管理添加神通数据源和人大金仓数据源的接入。

数据源管理添加Presto数据源的接入。

用户希望可以与神通和人大金仓数据源对接,支持后续做数据的深度挖掘。在数据管理模块添加神通、人大金仓数据源,填写数据源名称,URL,用户名和密码,点击测试,测试连接成功之后,在数据源管理列表中显示一条记录。
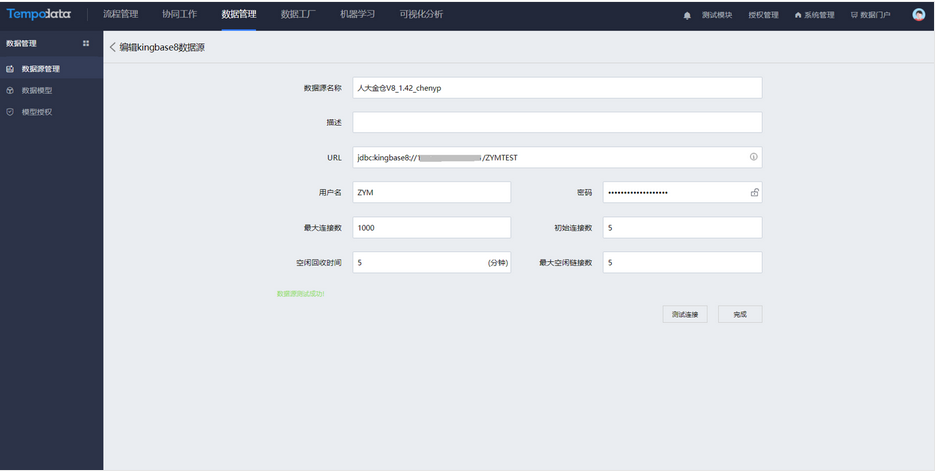
在机器学习模块,选择关系数据库输入节点,将神通/人大金仓数据源的表拖拽至右侧,形成SQL语句。测试成功之后,可查看数据内容和数据结构。
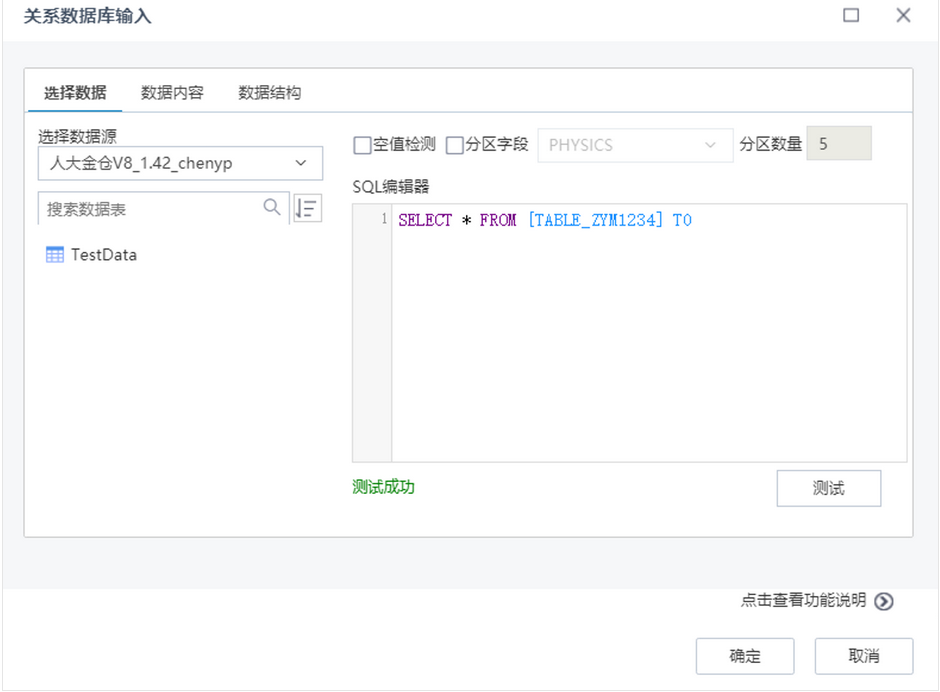
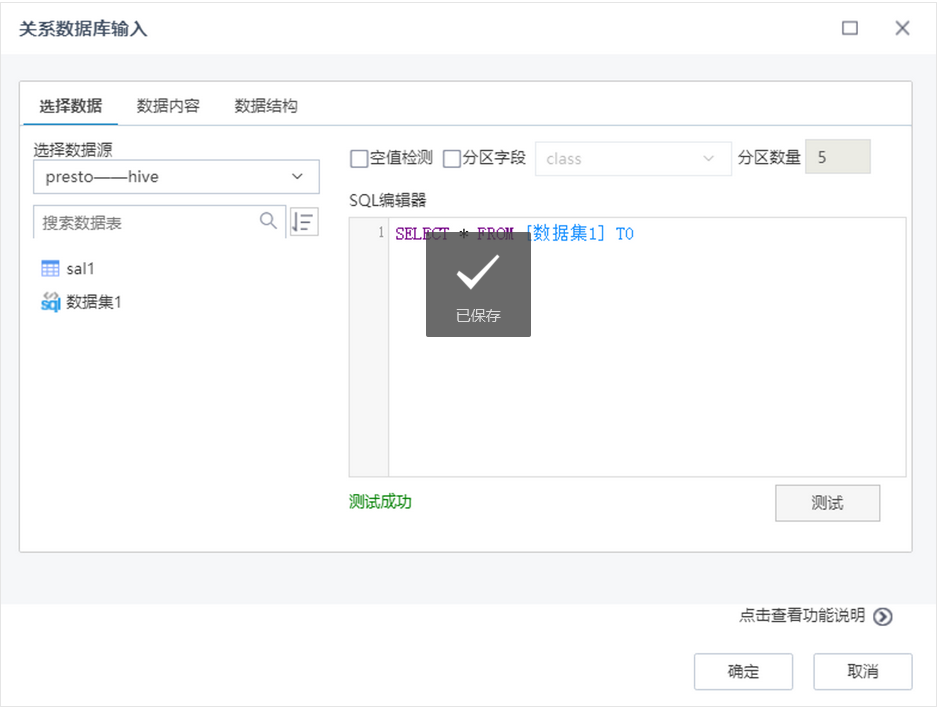
用户希望可以与Presto数据源对接,支持后续做数据的深度挖掘。在数据管理模块添加Presto数据源,填写数据源名称,URL,用户名和密码,点击测试,测试连接成功之后,在数据源管理列表中显示一条记录。
在机器学习模块,选择关系数据库输入节点,将Presto数据源的表拖拽至右侧,形成SQL语句。测试成功之后,可查看数据内容和数据结构。
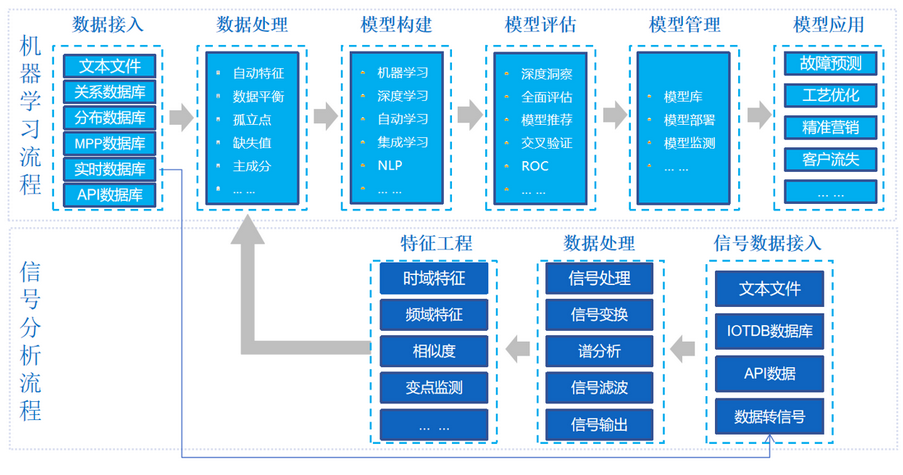
新增信号分析模块,支持30个信号分析算法,面向企业级用户的“信号分析+机器学习”模型开发及应用平台。
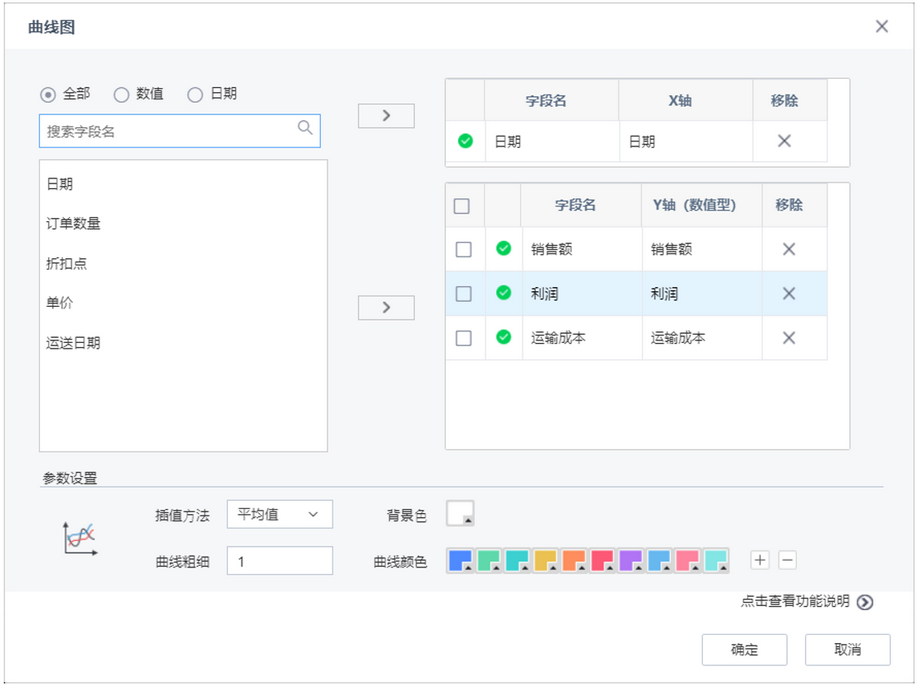
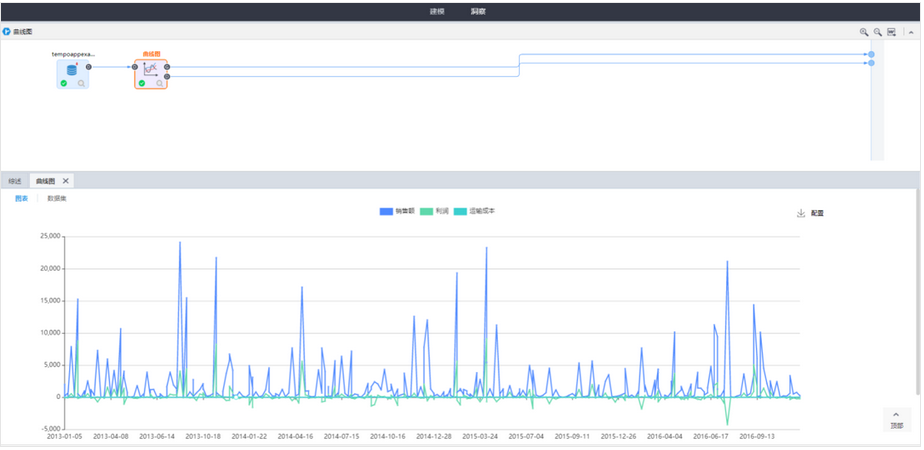
用户希望可以在机器学习模块通过曲线图展示数据情况。在要素库中的图表分析模块新增曲线图,曲线图节点主要接收前置节点端⼝传入的数据,进⾏单条曲线或多条曲线图的绘制。当数据量比较大时,会进行抽样展示,方便用户了解数据的趋势。建议Y轴的变量个数不超过20。注:曲线图是对总数据进行抽样展示,每个Y值抽样1万个点进行图表展示,方便用户了解数据的总体趋势。
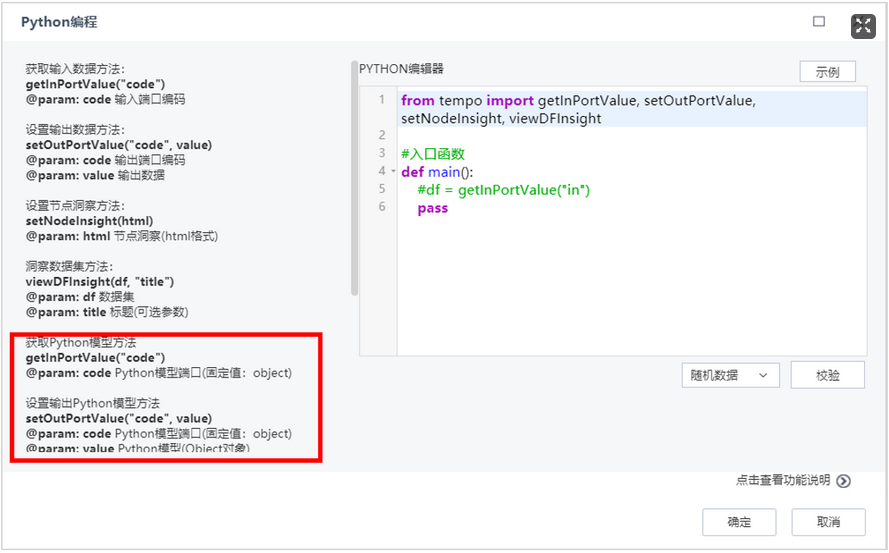
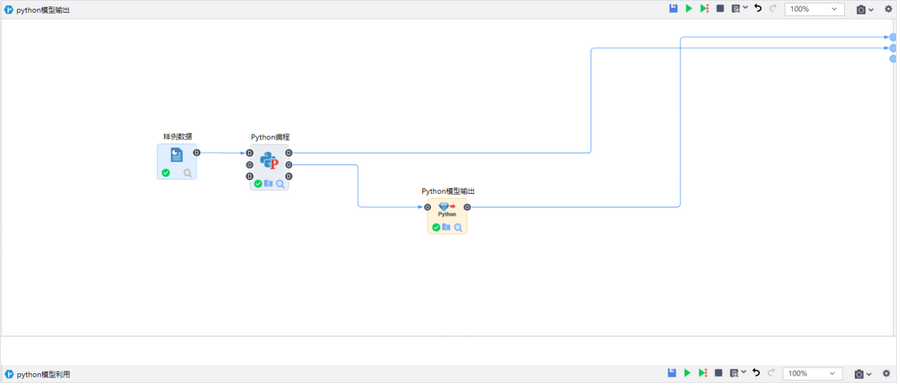
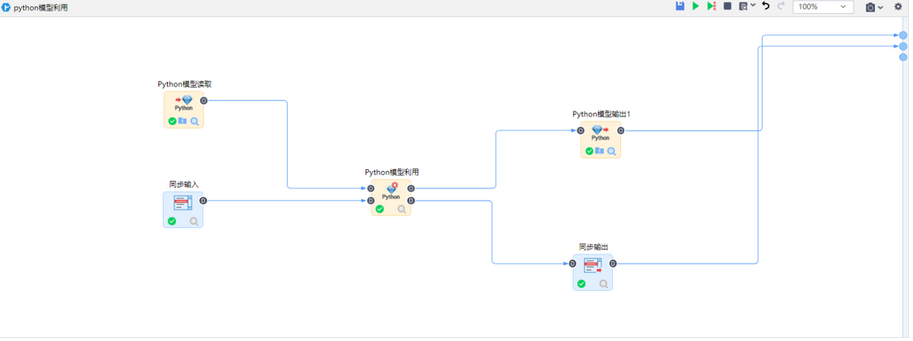
用户希望Python编程节点更灵活,支持输出模型,并且在平台中可以进行Python模型的输出、读取和利用。因此要素库中模型管理模块新增Python模型输出、Python模型读取和Python模型利用。支持用Python编程节点输出Python模型,在Python模型输出节点将模型落地到服务器,Python模型读取节点可以读取已经输出的模型,或者上传已保存的Python模型,最后通过Python模型利用节点实现数据处理、数据分析等功能。丰富建模过程中处理、算法的方法,使得数据建模过程更加灵活。
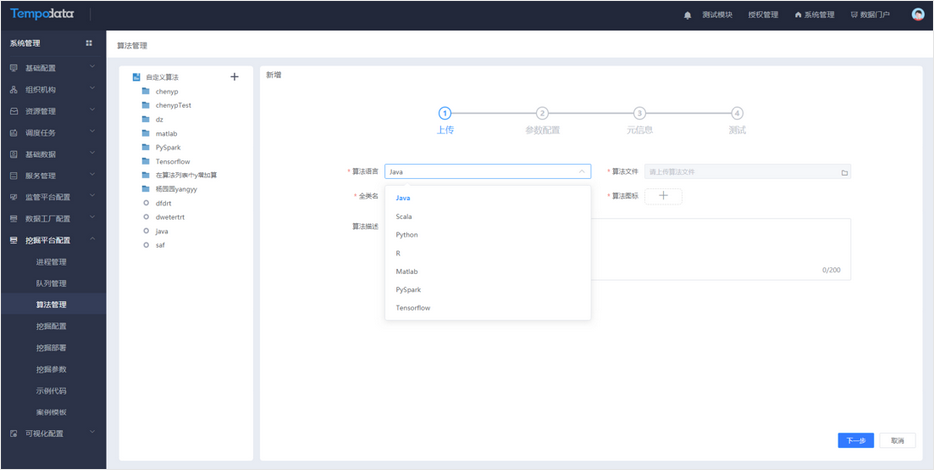
用户希望在自定义算法中可以支持Matlab、TensorFlow 、Pyspark。可以通过自定义算法模块选择Matlab、TensorFlow 、Pyspark,并上传相关的算法文件及参数配置,测试成功之后,可生成新的节点,后期方便使用。
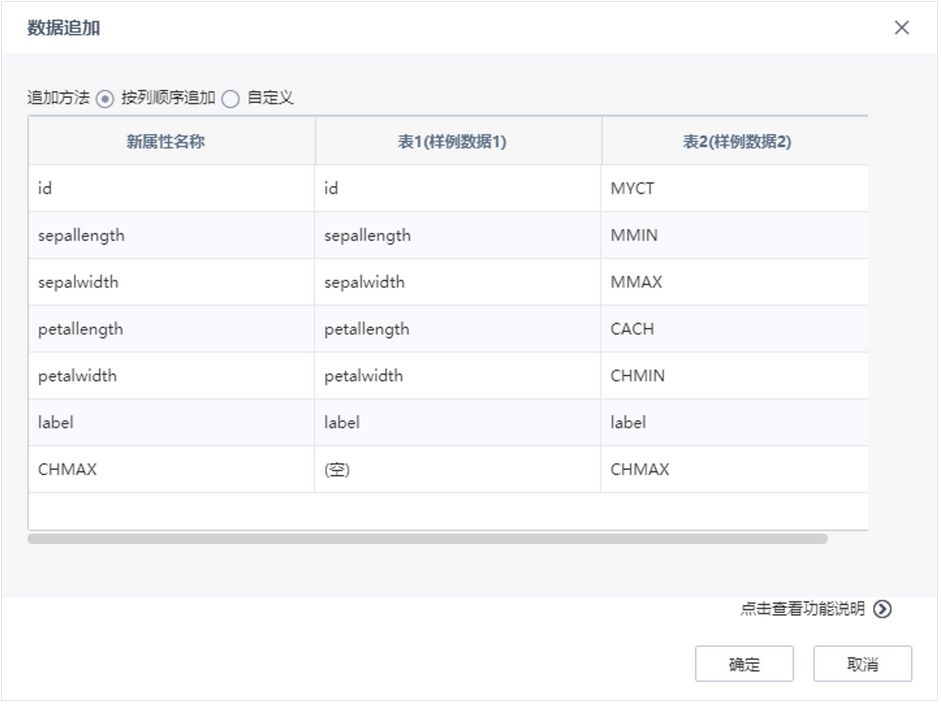
数据追加之前版本两张表的字段个数必须保持一致,若不一致,直接不可追加,目前对其进行优化,支持将两个或多个类似数据表的行进行连接,追加成一个新的数据集。匹配的属性列必须具备同样的数据类型,支持按列顺序和自定义方式进行表追加,结果数据集包含各个输入表中的每行。
用户编写 python 代码有问题,点击校验,将一直运行不能停止,Python进程持续消耗CPU和内存,导致当前服务器上面的其他服务无法访问。为了解决该问题,实现对当前python校验在系统管理中挖掘参数下添加时间限制设置,其次对提交python任务增加内存和CPU的设置机制。Python资源限制默认关闭,若需要开启,由系统管理员在系统管理—挖掘平台配置—挖掘配置,开启Python资源配置。
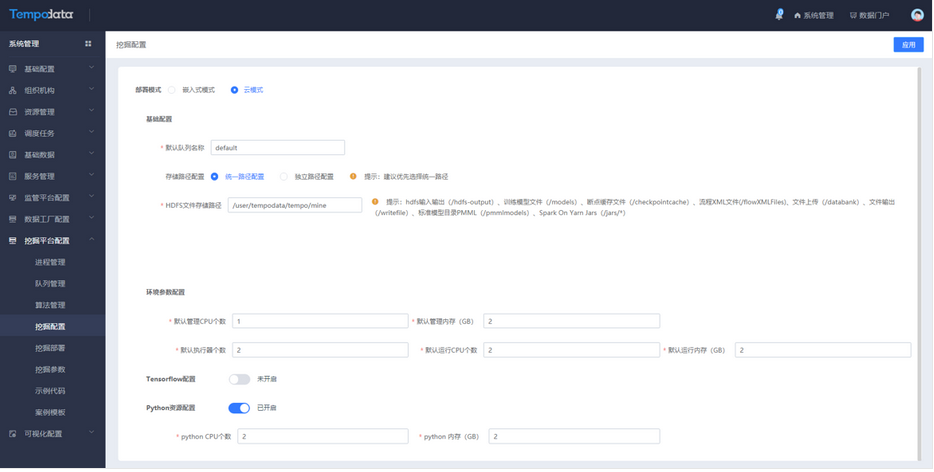
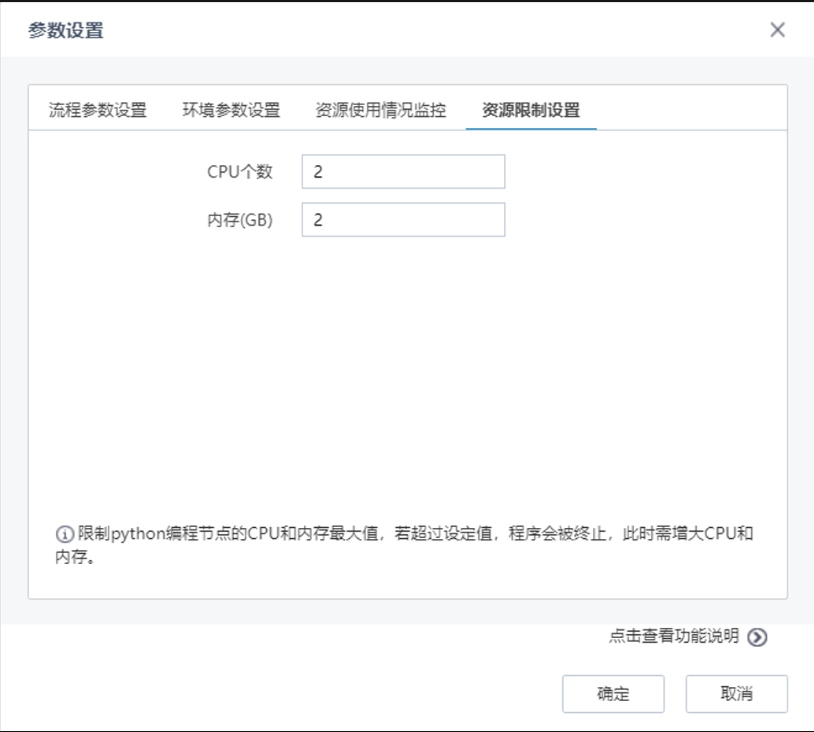
若Python资源配置开启,对本地、集群下及当前使用Python校验时,可进行资源限制,限制Python编程节点的CPU和内存的最大值,若超过设定值,程序会被终止,此时需增大CPU和内存。
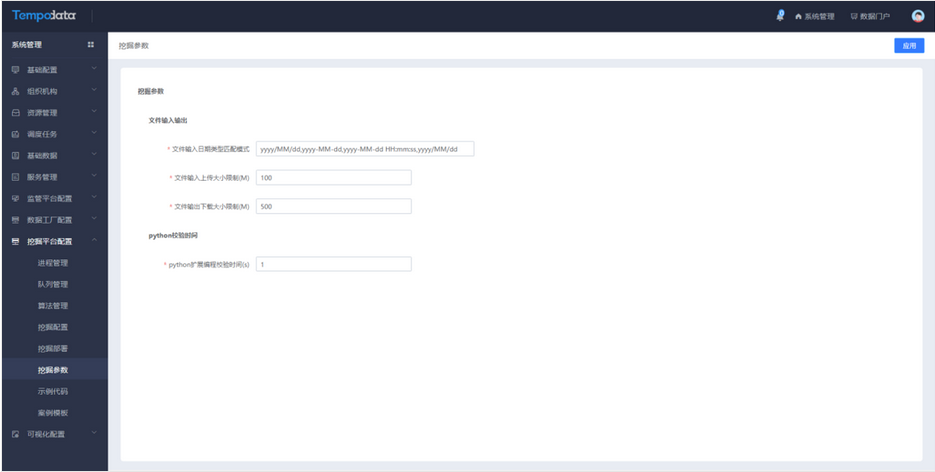
在挖掘参数中增加文件输入上传大小限制和python扩展编程校验时间的限制。
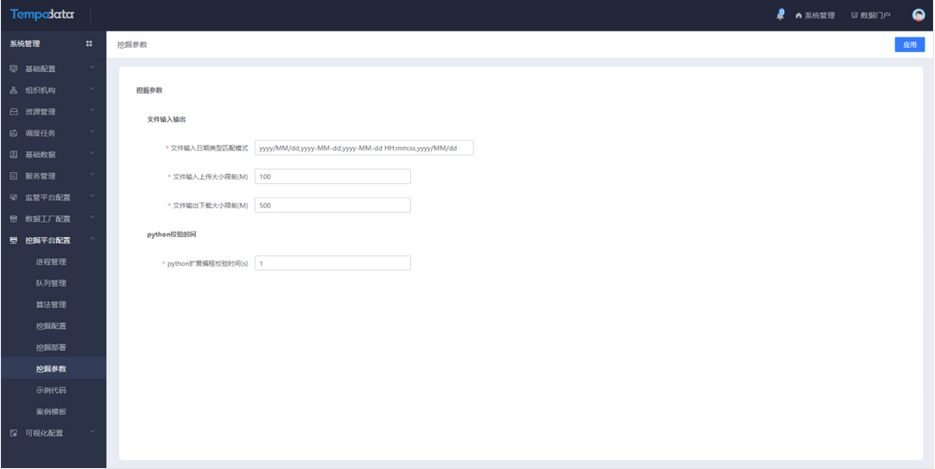
文件输入主要是在点击文件上传时,若文件大于限制,则无法进行上传,需要在挖掘参数中进行修改。
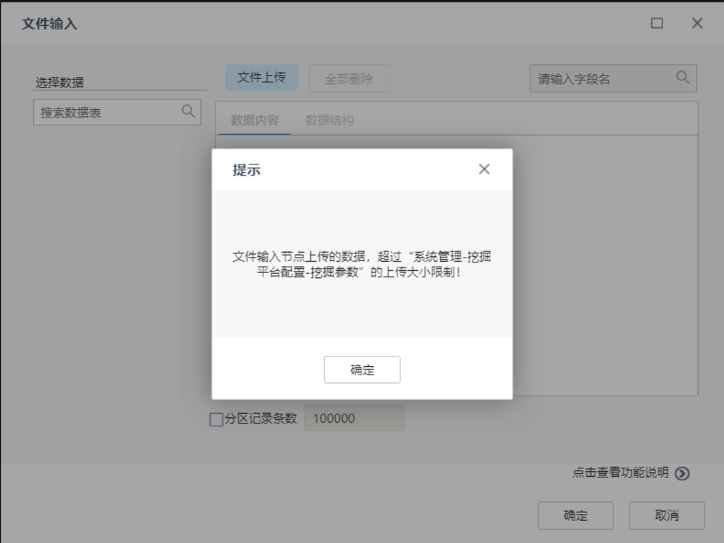
在文件输入节点,点击文件上传时,若文件大于限制,则无法进行上传,需要在挖掘参数中进行限制修改。
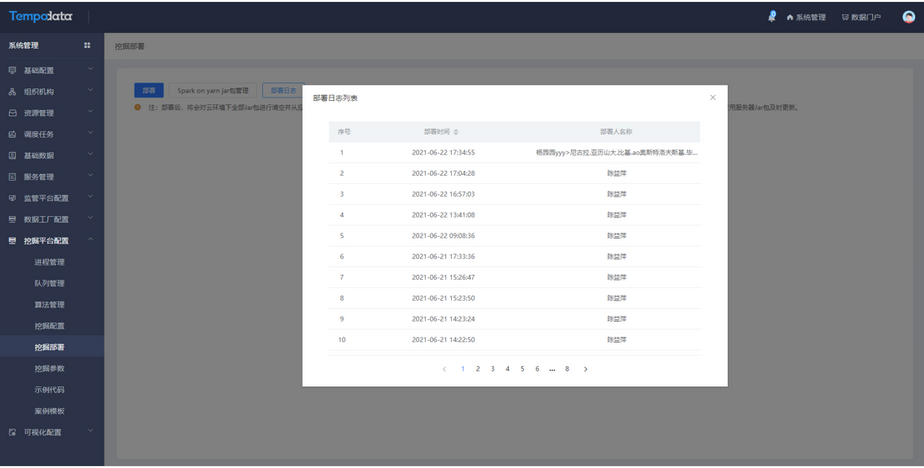
在挖掘部署中支持查看部署日志,可追溯点击部署的时间和人员,方便跟踪记录。
全国服务电话:
企业邮箱:tempo@meritdata.com.cn
地址:中国西安 ▪ 雁塔区西三环天谷八路软件新城国家电子商务示范基地六层


 陕公网安备 61019002000171号
陕公网安备 61019002000171号



