 方案咨询
方案咨询


























 Tempo大数据分析平台
Tempo大数据分析平台 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo数据资产管理平台
Tempo数据资产管理平台 Tempo主数据管理平台
Tempo主数据管理平台

服务热线
400-608-2558
咨询热线
029-88696198

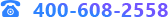

此次TempoAI V6.2主要侧重于增加数据管理、数据处理模块中的算子,以及用户体验、易用性和性能优化,并且修复了部分产品问题。
一、重点新特性
支持大数据引擎-Impala数据源;
支持时序数据库-IoTDB数据源;
新增批量文件输入节点;
新增过程查询分析器节点;
流程中某个节点报错,洞察支持查看执行成功节点的洞察信息;
系统管理—挖掘部署模块优化;
二、其它新特性
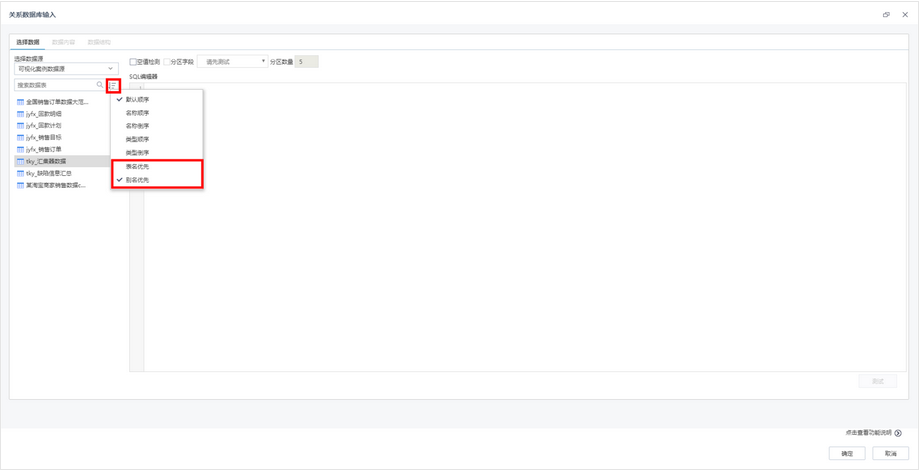
关系数据库输入/输出、HIVE输入/输出支持表名和别名优先;
自定义算法优化;
异常日志处理机制优化;
文件输入和输出性能优化;
关系数据库输入和输出性能优化;
关系数据库输入、关系数据库输出、Hive输入节点树形组件性能优化;
数据模型按人授权支持选中人员查看所有权限;
数据模型和关系数据库输出节点支持自定义过滤列名特殊字符,防止计算报错;
工作空间关注置顶功能;
空间权限、应用权限支持批量授权;
三、更新内容
3.1 数据管理
3.1.1 数据模型按人授权支持选中人员查看所有权限
原模型授权处对于模型按照组织机构、角色、组、人员进行授权是相互独立的,人员最终的权限为4个菜单授权的并集。但这种模式下无法支持选中某一人员后查看该人员的所有权限。本次更新对该功能进行优化,选中人员后,右侧不仅能够直接显示授予该人员的权限,也能够显示从组织机构、角色、组中继承过来的权限(继承权限只能查看无法修改),而且鼠标悬浮于继承图标上会显示继承来源。该功能的优化让数据管理员能够实现具体人员权限的快速查询,增强数据模型权限管理的便捷性。
3.1.2 数据模型和关系数据库输出节点支持自定义过滤列名特殊字符,防止计算报错
部分客户的业务数据中,列名可能包含了特殊字符,这些特殊字符导致在TempoBI通过这些列做计算时无法通过语法校验,影响用户的正常使用。对于该问题,我们通过在系统后台中提供参数,通过配置自动过滤特殊字符。
在系统后台nacos中,进入【配置管理-配置列表】,然后进入common-tempo-base.properties中,tempo.base.tempo_specialchar_filters定义了需要过滤的特殊字符。系统目前默认配置如下:
#特殊字符过滤
tempo.base.tempo_specialchar_filters=\n`~!@#$%^&*()+=|{}'':;,\\\[\\\].<>/?~!@#¥%&*[-]()——+|{}【】’;:”“‘。,、?·"《》
为了保持统一,在机器学习的关系数据库输出节点,增加字段描述的特殊字符校验,也是在系统后台nacos中,进入【配置管理-配置列表】,然后进入common-tempo-base.properties中,tempo.base.tempo_specialchar_filters定义了需要过滤的特殊字符。
3.2 机器学习
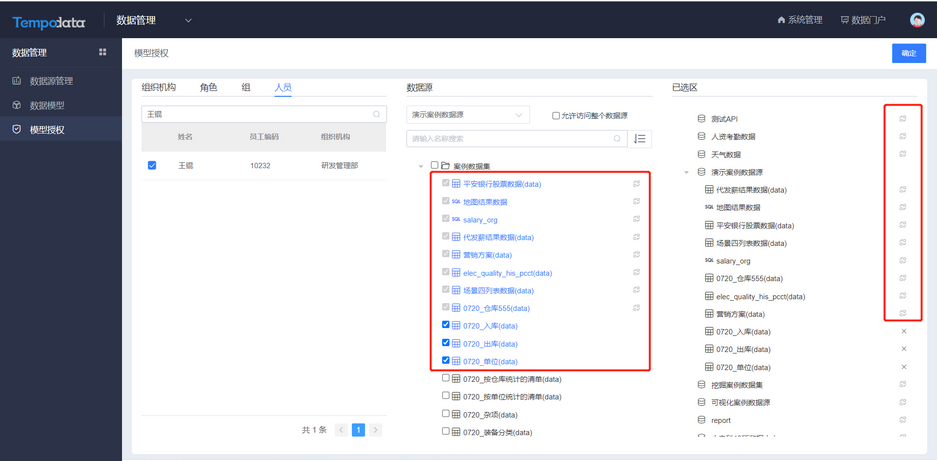
3.2.1 支持Impala数据源
用户希望可以与Impala数据源对接,支持后续做可视化分析或数据深度挖掘。在数据管理模块添加Impala数据源,填写数据源名称,URL,用户名和密码,点击测试,测试连接成功之后,在数据源管理列表中显示一条记录。
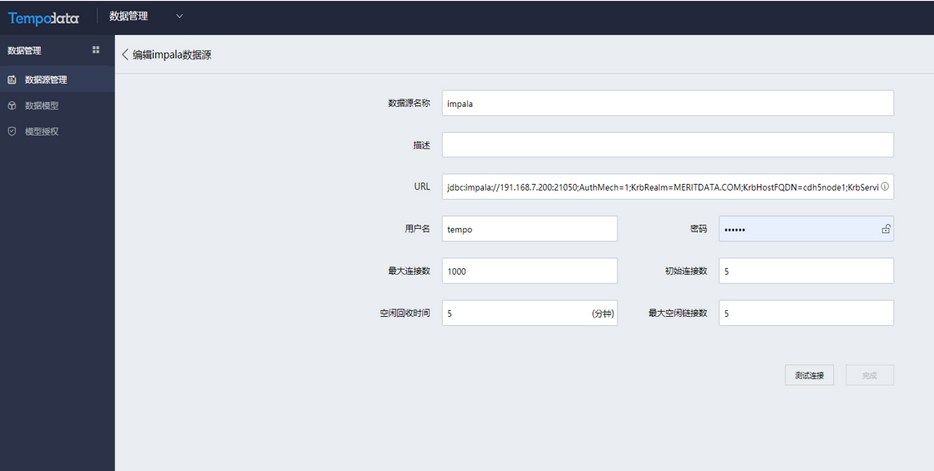
在机器学习模块,选择关系数据库输入节点,将Impala数据源的表拖拽至右侧,形成SQL语句。测试成功之后,可查看数据内容和数据结构。
流程更简
3.2.2 支持IoTDB数据源
用户希望可以与时序数据IoTDB数据源对接,支持后续做可视化分析或数据深度挖掘。在数据管理模块添加IoTDB数据源,填写数据源名称,URL,用户名和密码,点击测试,测试连接成功之后,在数据源管理列表中显示一条记录。
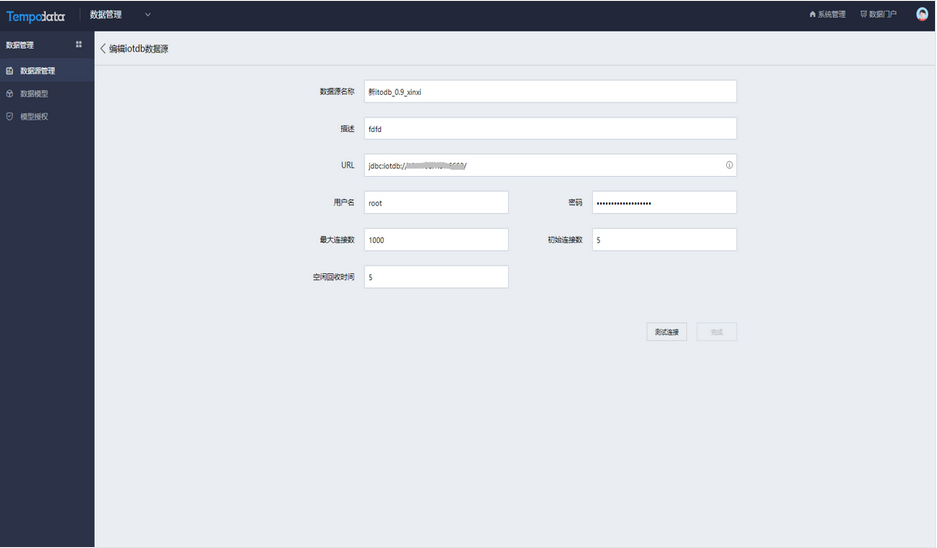
在数据管理中选择IoTDB输入节点,将需要的表拖至右侧,形成SQL语句,读取时序数据。
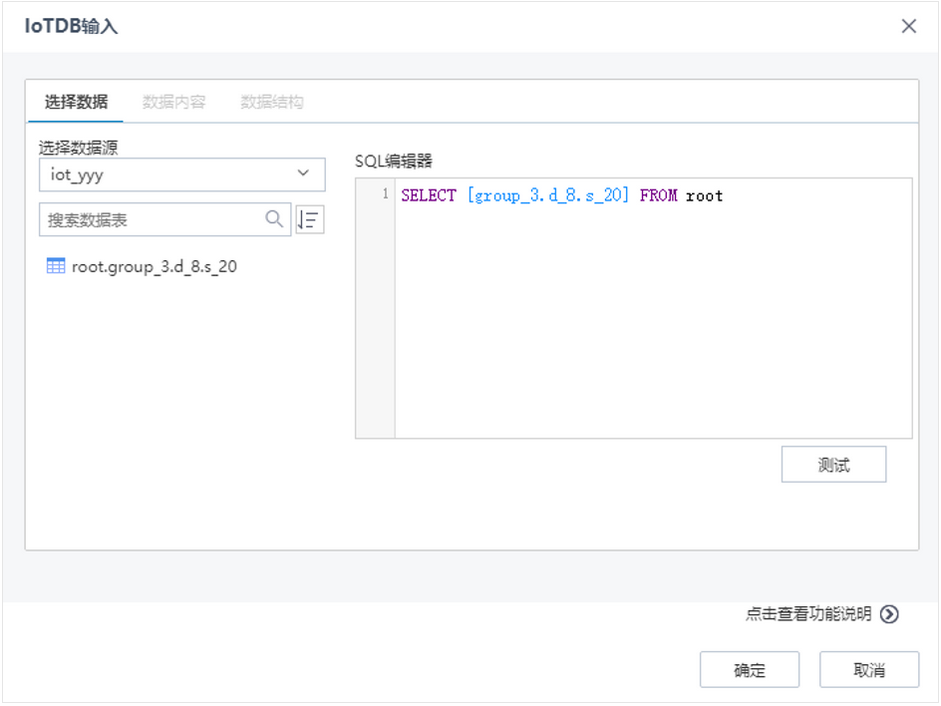
3.2.3 批量文件输入
新增批量文件输入节点,支持上传多个文件进行数据追加,作为挖掘分析数据源。该节点主要针对于用户有多个字段相同的表需要进行追加的使用场景,比如用户每月产生一个表,每月的表所有字段名称、字段类型、字段个数都是相同的,使用批量文件输入节点可以直接将多张表进行数据追加,便于后面的分析,提高用户使用的便捷性。
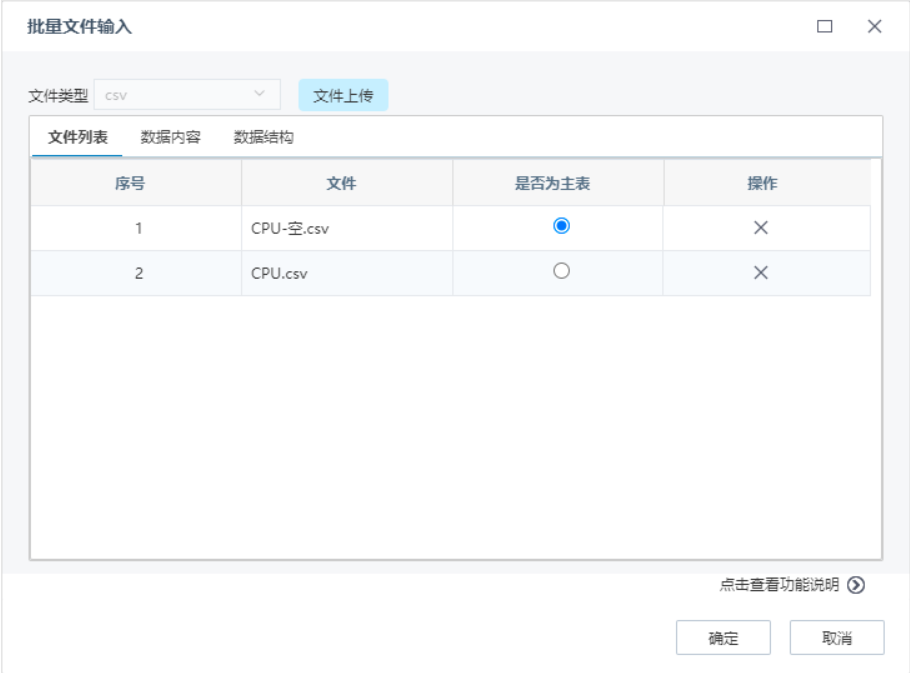
3.2.4 过程查询分析器
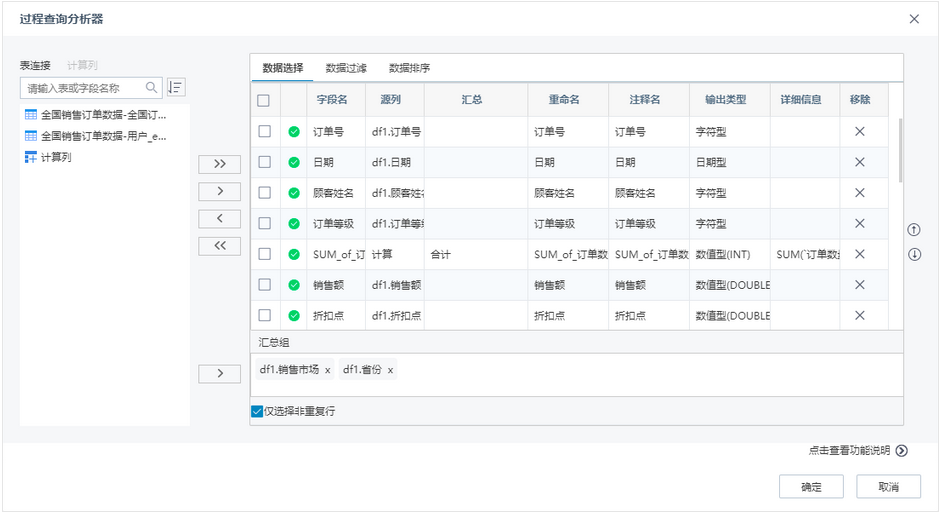
新增过程查询分析器节点,可实现对数据的处理过程,满足用户所需的多种组合算子功能,支持对数据进行表连接、计算列、数据选择、数据过滤、数据排序、汇总、去重等操作,实现接入数据的查询分析过程。
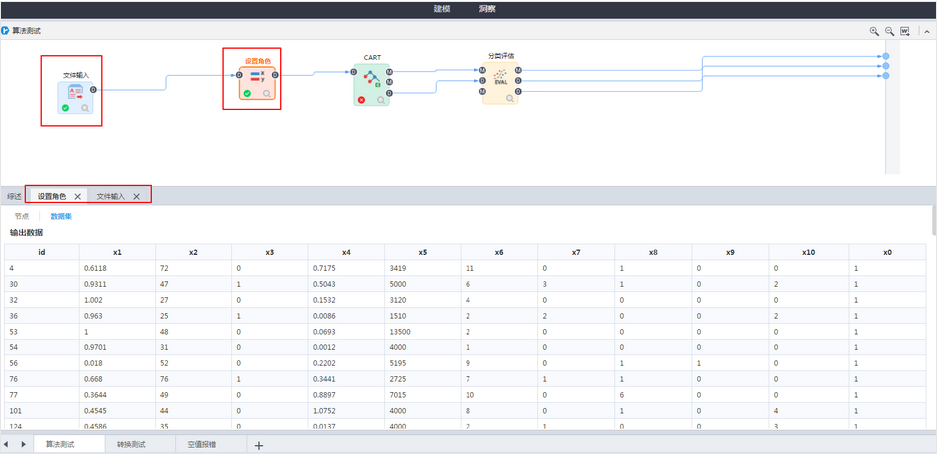
3.2.5 流程中某个节点报错,洞察支持查看执行成功节点的洞察信息
一般在设计流程阶段,会因为对节点功能不了解或参数配置不正确而执行报错,此时在洞察中查看不到已经执行成功节点的内容,不方便用户对结果进行追踪。现对于这种机制进行改进,流程中某个节点报错,这个节点之前执行成功的节点,可在洞察区查看它们的洞察结果信息。
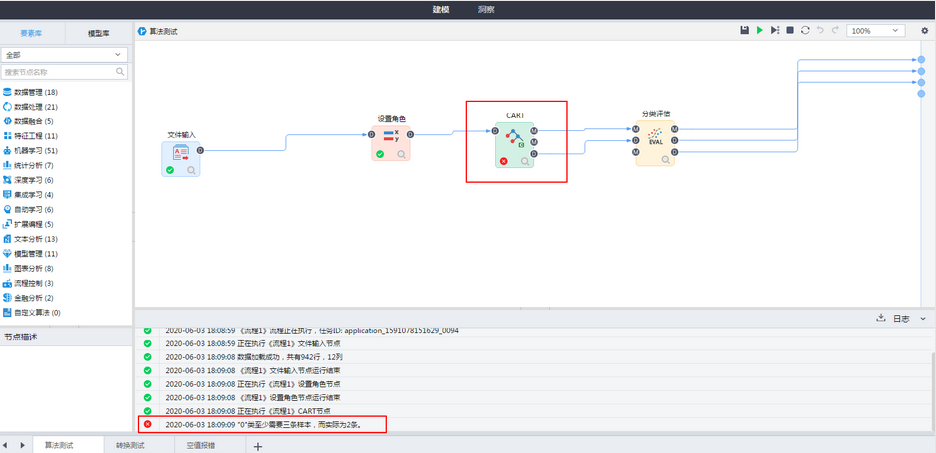
洞察查看结果:
3.2.6 系统管理—挖掘部署模块优化
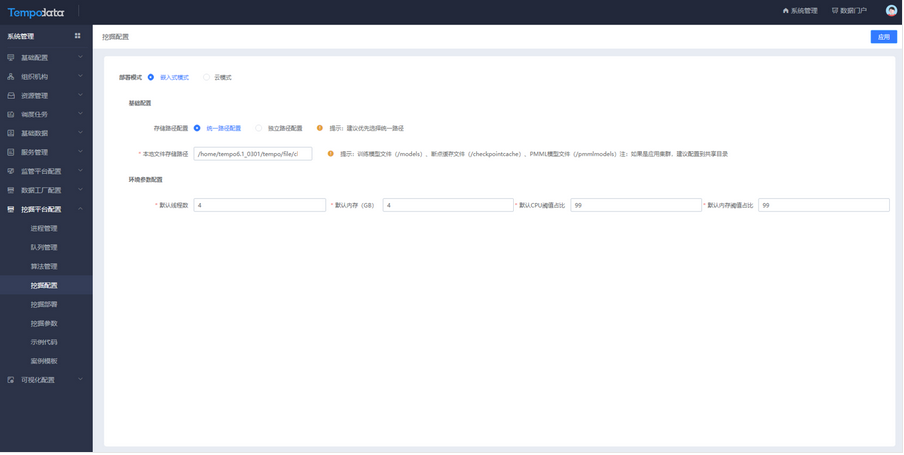
为了更符合用户的操作场景,将挖掘平台配置分为挖掘配置和挖掘部署,挖掘配置为用户提供嵌入模式和云模式两种部署模式,每种部署模式可进行配置;挖掘部署是根据用户选择的部署模型,自动识别部署方式进行部署操作。
嵌入式模式
挖掘配置模块选择嵌入式模式,在基础配置中,针对训练模型文件、断点缓存文件和PMML模型文件可选择统一路径配置和独立路径配置,然后在环境参数配置中填写默认的环境参数情况。
云模式
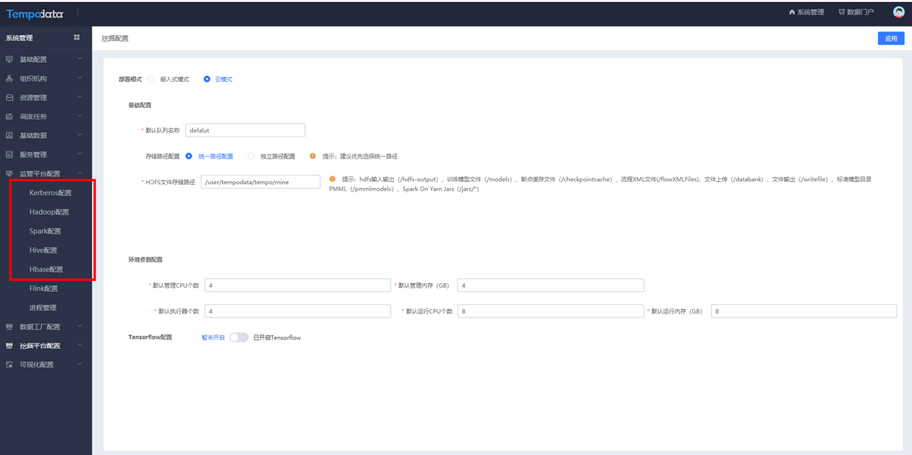
挖掘配置模块选择云模式,填写基础配置、环境参数配置和Tensorflow配置。
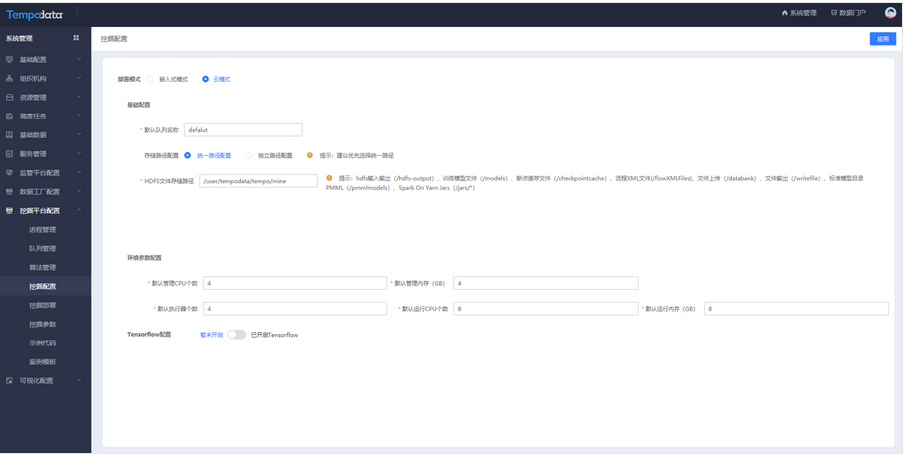
在监管平台配置中,配置Kerberos、Hadoop、Spark、Hive、Hbase的相关信息。
3.3 优化功能
1、关系数据库输入/输出、HIVE输入/输出支持表名和别名优先;
2、自定义算法优化;
3、异常日志处理机制;
4、文件输入和输出性能优化;
5、关系数据库输入和输出性能优化;
6、关系库输入、关系输出节点、Hive输入节点树形组件性能优化;
全国服务电话:
企业邮箱:tempo@meritdata.com.cn
地址:中国西安 ▪ 雁塔区西三环天谷八路软件新城国家电子商务示范基地六层


 陕公网安备 61019002000171号
陕公网安备 61019002000171号



