大话数据挖掘——预测分析之决策树方法
2021-03-02 18:18:58
次
接上一篇《大话数据挖掘之预测分析》
徐教授的PPT又翻开了新的一页,他将光笔指向屏幕上的树状图,讲道:“所谓决策树就是一个类似流程图的树型结构,树的最高层结点就是根结点,树的每个内部结点代表对一个属性(取值)的测试,其分支就代表测试的每个结果,而树的每个叶结点就代表一个类别。从根节点到叶子节点的每一条路径构成一条‘IF…THEN…’分类规则。”
李部长凝视着大屏幕上的决策树,明白了其中的奥妙,不禁道:“决策树方法实际上就是通过一定的评判策略判定哪一个属性对分类最为重要,就将其作为根节点,然后再判断余下的节点中最重要的的节点,直到叶子节点。”
“好,理解得还比较透彻。不过,李部长,什么样的节点才可以标注为叶子节点呢?”徐教授问。
李部长吱吱唔唔:“好像有三种情况……”
“对,附合以下三个条件之一的节点就可为叶子节点:(1)节点的样本集合中所有的样本都属于同一类;(2)节点的样本集合中所有的属性都已经处理完毕,没有剩余属性可以用来进一步划分样本,这时候采用子集中多数样本所属于的类来标记该节点;(3)节点的样本集合中所有样本的剩余属性取值完全相同,但所属类别却不同,此时用样本中多数类来标示该节点。”
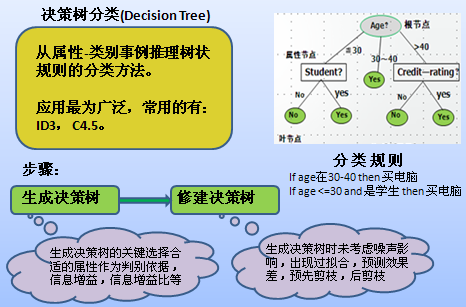
徐教授接着说:“决策树算法的典型代表是ID3(Interactive Dicremiser version 3)算法,它是由Quinlan等人于1986年提出的,是当前机器学习领域中最有影响力的算法之一。其核心思想是在决策树的构建过程中采取基于信息增益的特征选择策略,即选取具有最高信息增益的属性作为当前节点的分裂属性,使得对结果划分中的样本分类所需要的信息量最小。以此构造与训练数据一致的一棵决策树,从而保证了决策树具有最小的分支数量和最小的冗余度。”
李部长:“ID3算法思想简单,并且由其构造的决策树对样本的识别率比较高。在实际应用中,ID3算法还有什么不足之处吗?”
徐教授按了一下光笔,并说:“请看大屏幕ID3算法的缺点主要表现在以下几个方面。”
ID3算法的不足之处
(1)ID3算法在搜索过程中不能再回溯重新考虑选择过的属性,从而收敛到局部最优解而不是全局最优解;
(2)信息增益的度量偏袒于属性取值数目较多的属性,这不太合理;
(3)ID3算法只能处理离散值得属性,不能处理连续属性;
(4)当训练样本过小或者包含有噪声的时候,容易产生过度拟和(Overfitting)现象。
马处长看着屏幕,问道:“徐老师,那怎样改进ID3算法呢?”
徐教授回答道:“针对ID3算法的不足,Quinlan于1993年提出了ID3的改进的方法——C4.5。与ID3相比,C4.5主要在以下几个方面作了修改,并且引进了新的功能:用信息增益比率作为选择标准,弥补了ID3算法偏向于取值较多的属性的不足;合并连续属性的值;可以处理具有缺少属性值的训练样本;运用不同的剪枝技术来避免决策树的过拟合现象;K次交叉验证等等。”
李部长又问:“徐老师,我们在使用决策树算法进行分类时,有时会出现过拟合现象,这是怎么回事呢?”
徐教授不厌其烦:“基本的决策树构造算法没有考虑噪声,因此生成的决策树可以完全与训练数据拟合,也就是说,对训练数据的测试准确度可以达到100%。但是在有噪声的情况下,完全拟合将导致“过拟合”的结果,即对训练数据的完全拟合反而导致对新数据的预测能力下降。这是因为当训练数据集合包含噪声时,决策树在生成的过程中为了与训练数据一致,必然生成了一些反映噪声的分支,这些分支不仅在新的决策问题中导致错误的预测,而且增加了模型的复杂度。”
马处长也问道:“那怎么避免过拟合现象呢?”
徐教授:“解决决策树生成过程中的过拟合问题的方法主要是对决策树进行剪枝。剪枝是一种克服噪声的技术,它有助于提高决策树对新数据的准确分类能力,同时能使决策树得到简化,使其更容易理解,加快分类速度。剪枝策略可分为预剪枝(pre-pruning)和后剪枝(post-pruning)两种。预剪枝主要是通过建立某些规则限制决策树的充分生长,后剪枝则是等决策树充分生长完毕后再剪去那些不具有一般代表性的叶节点或者分枝。尽管前一种方法可能看起来更直接,但是后一种方法在实践中更成功。因此在实际运用中更多的采用的是后剪枝技术。”





























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台








 陕公网安备 61019002000171号
陕公网安备 61019002000171号



