时间序列数据挖掘:利用机器学习揭示趋势和模式
2023-12-14 16:17:00
次
随着数据技术的不断发展和普及,数据分析和数据挖掘成为了企业和组织在日常运营和战略决策中不可或缺的工具。而时间序列分析,作为一种重要的数据分析和数据挖掘方法,已经被广泛应用于各个领域,如金融、经济、市场营销等。通过对时间序列数据的分析,可以发现潜在的规律和趋势,帮助决策者更准确地预测未来市场走向、评估风险和机会,制定更加优化的战略或运营计划。本文将介绍时间序列分析的基本概念和方法,以及如何利用数据分析、数据挖掘等技术对这种方法进行优化和改进。
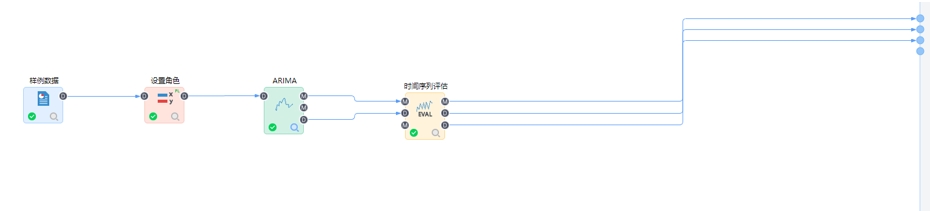
第一步接入数据:
时间序列算法要求接入结构化数据,自变量数据类型为数值型,不支持字符型、日期型和文本型等。若接入的自变量数据不满足时间序列分析的数据要求,可以通过属性变化节点进行数据类型转换或重新接入数据。
第二步设置角色:
通过设置角色节点确定时间序列分析研究的属性列,设置为自变量。时间序列算法必须设置自变量,不支持设置因变量,自变量仅支持连续型(数值)属性,并且只能有一个自变量。
一般建议在设置角色之前先进行数据的可视化探索,利用平台提供的图表分析节点,如散点图等识别序列是否是非随机序列,如果是非随机序列,则观察其平稳性。对非平稳的时间序列数据采用差分进行平稳化处理,直到处理后序列是平稳的非随机序列。因为对于时间序列数据,最重要的检验就是时间序列数据是否为白噪声数据、时间序列数据是否平稳,以及对时间序列数据的自相关系数和偏自相关系数进行分析。如果时间序列数据是白噪声数据, 说明其没有任何有用的信息。针对时间序列数据的很多分析方法,都要求所研究的时间序列数据是平稳的,所以判断时间序列数据是否平稳,以及如何将非平稳的时间序列数据转化为平稳序列数据,对时间序列数据的建模研究是非常重要的,如果模型没有通过检验(检验模型残差序列是否为白噪声序列),需要对其进行重新识别。
第三步建立数据分析模型:
根据业务分析方案和所识别出来的特征建立相应的时间序列模型。平台内置9种时间序列算法可以直接拖拽使用,并配置对应的模型参数,包括:ARIMA、稀疏时间序列、指数平滑、移动平均、向量自回归、X11、X12、回声状态网络和灰色预测。当我们不清楚当前数据更适合哪种时间序列算法,或不清楚多个模型中哪个模型效果更好时,我们有两种处理方案:方案一,通过多分支节点将自变量相同的输入数据同时传递给多个不同的时间序列模型,由平台推荐出多个模型中的最优模型;第二种,通过自动时序节点选择多个时间序列算法一次性构建模型,该节点内嵌自动择参功能,将多个算法及其对应的多组参数生成的多个模型进行评估比较,最终帮助我们推荐出最佳算法及相应的最佳参数组合。
第四步数据分析模型评估:
利用时间序列评估节点检验时序模型的可靠性,在洞察中根据一些评价的指标(如相对误差等指标)或者图表展示,获得质量最佳的时序模型。
完成上述建模之后执行流程,流程执行成功后自动跳转至洞察页面,在洞察页面点击可以查看模型的分析结果,我们通过示例流程来详细介绍。点击【ARIMA】查看模型结果,包含预测值真实值对比曲线图、自相关图、偏相关图及统计检验量。

点击【时间序列模型评估】查看模型对历史数据预测的评估如下:
从误差来看,模型的平均相对误差为19%,所以模型结果比较一般。再来看数据集的情况,可以看到新增的prediction预测结果列。
第五步利用算法模型预测:
需要注意的是,平台中时间序列的模型不支持连接模型利用节点,对于新数据只能重新进行预测。那么在上述示例中模型构建完成后,就可以利用模型对系统容量进行预测,其模型应用过程如下:
1、从系统中每日定时抽取服务器磁盘数据;
2、对定时抽取的数据进行清洗、数据变换预处理等操作;
3、将预处理后的数据存放到数据库中,定时的调用流程对服务器磁盘进行预测,预测后四天的磁盘使用大小;
4、将预测值与磁盘的总容量比较,获得预测的磁盘使用率。如果某一天预测的使用率达到业务设置的预警级别,就会以预警的方式提醒系统管理员。





























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台





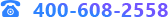




 陕公网安备 61019002000171号
陕公网安备 61019002000171号



