聚类分析是无监督学习,即我们事先不知道正确结果,数据没有附带标签,需要通过某些算法来发现数据内在的本质和规律,从而实现对数据内在关联结构的分类。聚类分析就是根据样本间的相似性对样本集进行分组,使得组内差距最小化,组间差距最大化。如:客户细分、用户画像、新闻聚类、基因分类等。为数据挖掘和业务分析提供了有力支持。
聚类分析流程步骤如下:
第一步接入数据:聚类算法要求接入结构化数据,自变量数据类型为数值型或字符型,不支持日期型和文本型。若接入的自变量数据不满足聚类分析的数据要求,可以通过属性变化节点进行数据类型转换或重新接入数据。
第二步设置角色:通过设置角色节点确定聚类分析研究的属性列,设置为自变量。聚类算法必须设置自变量,不支持设置因变量,自变量可以是连续型(数值)也可以是离散型(字符)。当然在设置角色节点之前也可以根据实际业务和数据情况进行原始数据的清洗、集成、转换、离散、归约、特征选择和提取等一系列预处理工作,达到挖掘建模的数据标准。
第三步建立模型:根据分析方案和处理后的业务数据构建聚类模型,平台内置9种聚类算法可以直接拖拽使用,并配置对应的模型参数,包括:KMeans、模糊C均值、EM聚类、Hierarchy、Kohonen聚类、视觉聚类、Canopy、幂迭代和两步聚类。当我们不清楚当前数据更适合哪种聚类算法,或不清楚多个模型中哪个模型效果更好时,我们有两种处理方案:方案一,通过多分支节点将相同的输入数据同时传递给多个不同的聚类模型,由平台推荐出多个模型中的最优模型;第二种,通过自动聚类节点选择多个聚类算法一次性构建模型,该节点内嵌自动择参功能,将多个算法及其对应的多组参数生成的多种模型进行评估比较,最终帮助我们推荐出最佳算法及相应的最佳参数组合。
第四步模型评估:利用聚类评估节点检验聚类模型的可靠性,在洞察中根据一些评价的指标(如总离差平方和等)或者图表展示,获得质量最佳的聚类模型。
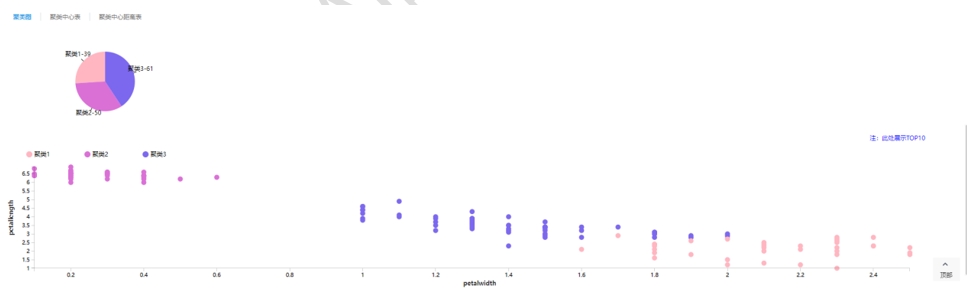
完成上述建模之后执行流程,流程执行成功后自动跳转至洞察页面,在洞察页面点击可以查看模型的分析结果,我们通过示例流程来详细介绍。点击【KMeans】查看聚类结果,在聚类图中以看到各类别的样本数,聚类1样本数39个,聚类2样本数50个,聚类3样本数61个,如下图所示:
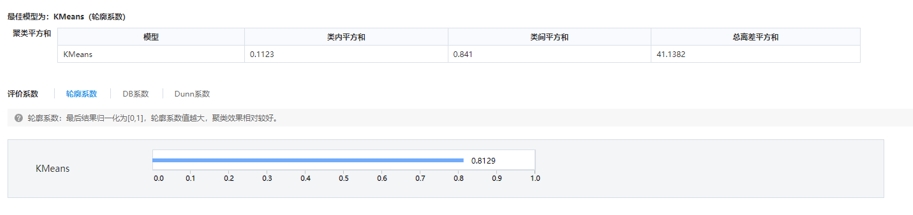
点击【聚类评估】查看模型的评估结果,如下图:
总离差平方和,值越小说明真实数值与期望值之间相差越小,可被用来评估模型的准确率。轮廓系数、DB系数、Dunn系数,3个系数均是值越大聚类效果越好。我们从聚类评估结果可以看出,KMeans算法的总离差平方和都比较小,轮廓系数值都在0.8以上,模型聚类效果较好。
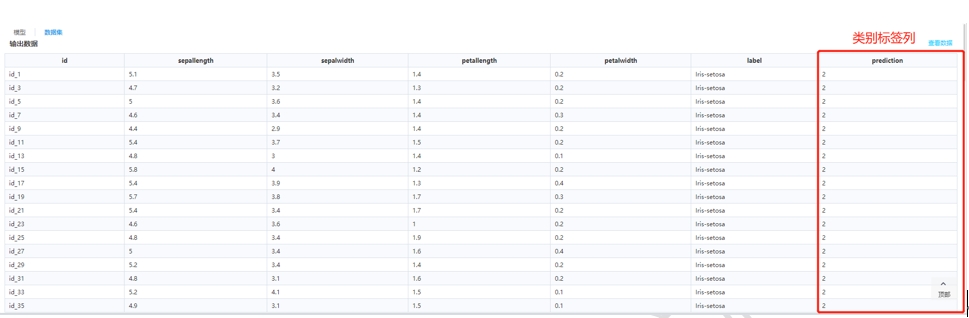
再来看数据集的情况,可以看到最后一列属性“prediction”为类别标签列。





























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台








 陕公网安备 61019002000171号
陕公网安备 61019002000171号



