数据挖掘实战指南:回归分析流程详解与模型预测
2023-12-11 18:00:18
次
回归分析作为一种数据挖掘方法,主要用于预测数值型数据,通过研究自变量和因变量之间的数量变化关系,可以帮助预测房价、股票的成交额、未来的天气情况等。属于有监督学习。
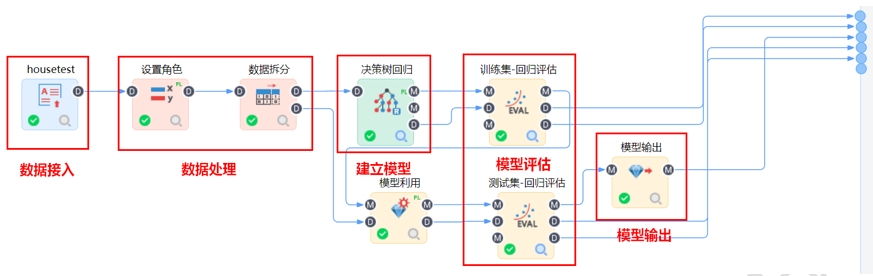
第一步接入数据:
回归算法要求接入结构化数据,自变量数据类型必须为数值型或字符型,不支持日期型和文本型。因变量只能为数值型。若接入自变量和因变量数据不满足回归分析的数据要求,可以通过属性变化节点进行数据类型转换或重新接入数据。数据的接入方式通过平台内置的数据输入节点,包括:关系数据库输入、文件输入、InfluxDB输入、HIVE输入、API输入等。
第二步设置角色:
根据预测目标,通过设置角色节点确定回归分析研究的自变量与因变量,评估自变量对因变量的具体影响。回归算法必须设置自变量,自变量可以是连续型(数值)也可以是离散型(字符),也必须设置因变量,且因变量只能是一个连续型(数值)。当然在设置角色节点之前也可以根据实际业务和数据情况进行原始数据的清洗、集成、转换、离散、归约、特征选择和提取等一系列预处理工作,达到挖掘建模的数据标准。可以利用平台内置的数据处理、数据融合和特征工程等节点,例如数据过滤、属性过滤、缺失值处理、数据标准化等进行数据预处理。
第三步数据拆分:
通常在解决实际问题时经常通过数据拆分节点把数据拆分为训练数据集和测试数据集。通过回归算法对训练数据集进行建模,寻找X和Y之间的数学模型,然后通过测试数据集来验证该数学模型的准确率,如果误差能够达控制到一定精度,则认为该模型很好的反映了X和Y的关系,可以用来进行预测和分析。
第四步建立数据挖掘模型:
根据分析方案和处理后的业务数据构建回归模型,平台内置9种回归算法可以直接拖拽使用,并配置对应的模型参数,包括:线性回归、决策树回归、随机森林回归、梯度提升树回归、BP神经网络回归、SVM回归、L1/2稀疏迭代回归、保序回归和曲线回归。当我们不清楚当前数据更适合哪种回归算法,或不清楚多个模型中哪个模型效果更好时,我们有两种处理方案:方案一,通过多分支节点将自变量和因变量相同的输入数据同时传递给多个不同的回归模型,由平台推荐出多个模型中的最优模型;第二种,通过自动回归节点选择多个回归算法一次性构建模型,该节点内嵌自动择参和交叉验证等功能,帮助我们在多种模型下选择和推荐出最佳的模型。当然在进行回归分析之前,我们可以先了解自变量和因变量之间的相关关系,以便判断后续采取回归模型的类型,比如通过图表分析类节点绘制图形或通过统计分析类节点进行相关性分析等都可以。
第五步数据挖掘模型评估:
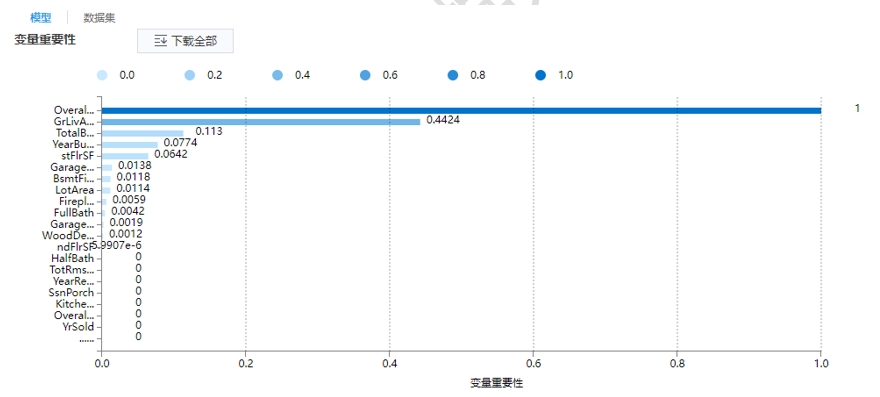
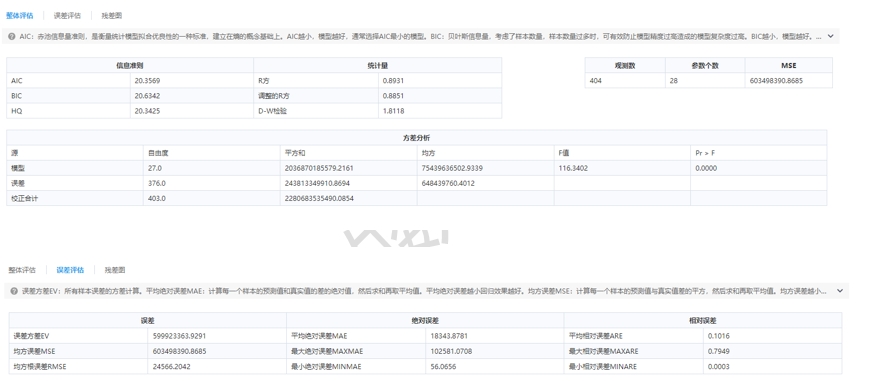
利用回归评估节点检验回归模型的可靠性,在洞察中根据一些评价的指标(如相对误差等指标)或者图表展示,获得质量最佳的回归模型。 完成上述建模之后执行流程,流程执行成功后自动跳转至洞察页面,在洞察页面点击可以查看模型的分析结果,我们通过示例流程来详细介绍。点击【决策树回归】查看变量重要性:
训练集评估结果:
测试集评估结果:
从R方上来看,训练集为0.93,测试集为0.89;从相对误差来看,训练集的平均相对误差为0.08,测试集的平均相对误差为0.1,误差相对较少;说明模型效果较好。
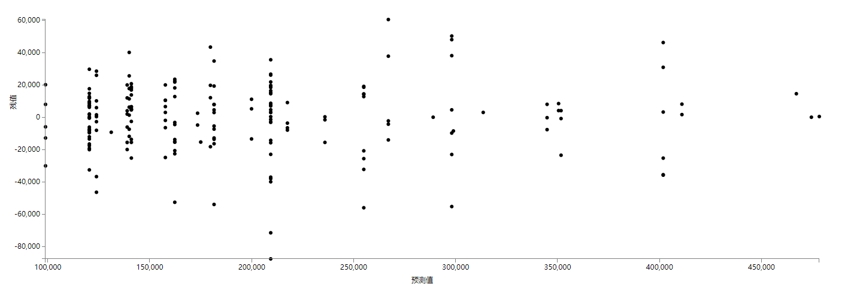
残差图:
从残差图中可以看出,误差在等于0的直线上下随机波动,因此残差不存在相关性,说明模型效果较好。
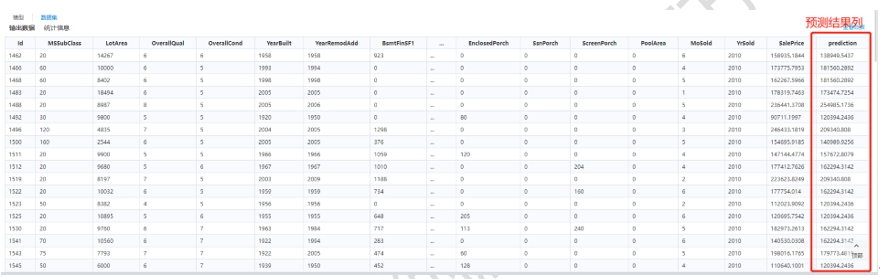
再来看数据集的情况,可以看到新增的prediction预测结果列。
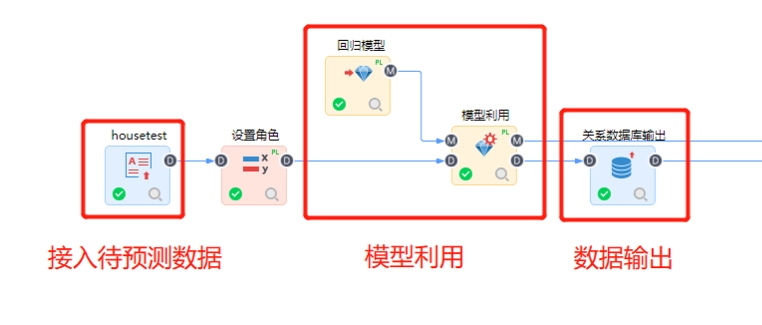
第六步利用模型预测:
训练好模型之后,通过模型输出节点将模型保存至模型库中,然后就可以利用训练好的模型进行预测,一般我们建议构建模型训练和模型预测两个流程。通过模型读取和模型利用节点进行预测流程的构建,并且可以将预测结果保存至数据库或本地excel中,便于我们构建BI可视化看板或其他第三方应用。如下图:





























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台





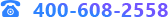



 陕公网安备 61019002000171号
陕公网安备 61019002000171号



