




























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台




服务热线
400-608-2558
咨询热线
15502965860-




 :
:
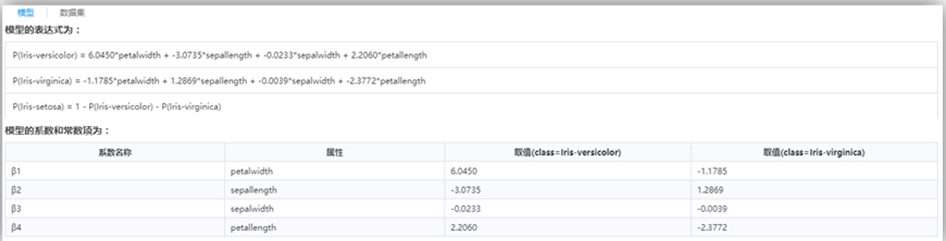
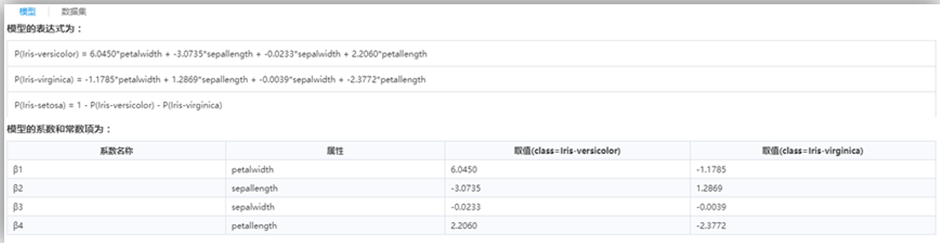
 为系数向量θ的常数项;θ_i为第i个自变量x_i的系数。
为系数向量θ的常数项;θ_i为第i个自变量x_i的系数。


 取得最大值的系数向量 θ 的估计值
取得最大值的系数向量 θ 的估计值 。
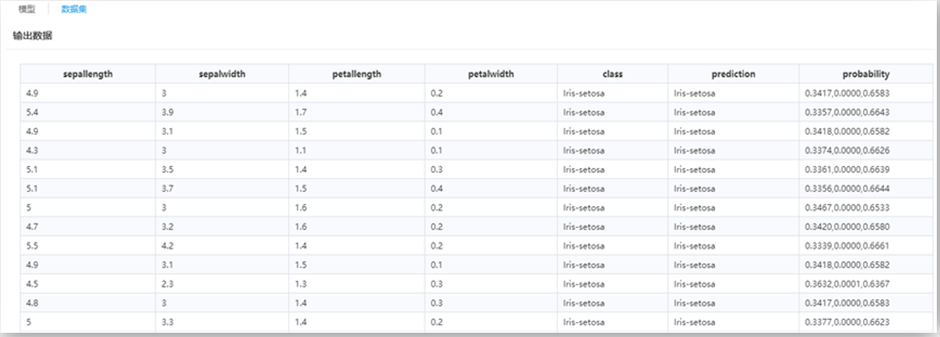
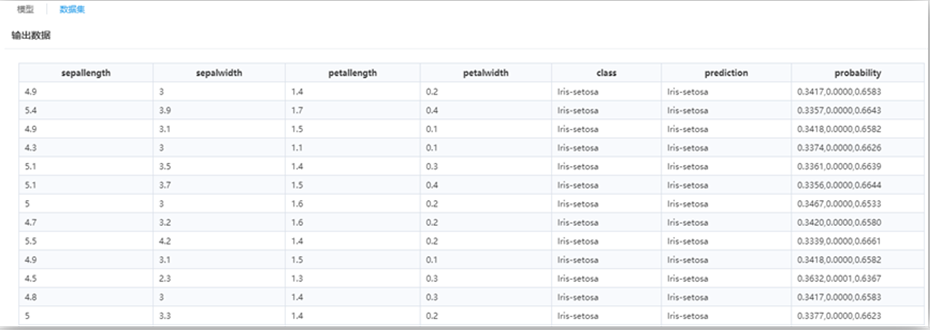
。 ,使用概率计算公式,分别计算出每个样本属于类别1和类别0的概率。
,使用概率计算公式,分别计算出每个样本属于类别1和类别0的概率。 (通常为0.5),对每个样本属于两类的概率进行截取,进而得到样本的所属类别。
(通常为0.5),对每个样本属于两类的概率进行截取,进而得到样本的所属类别。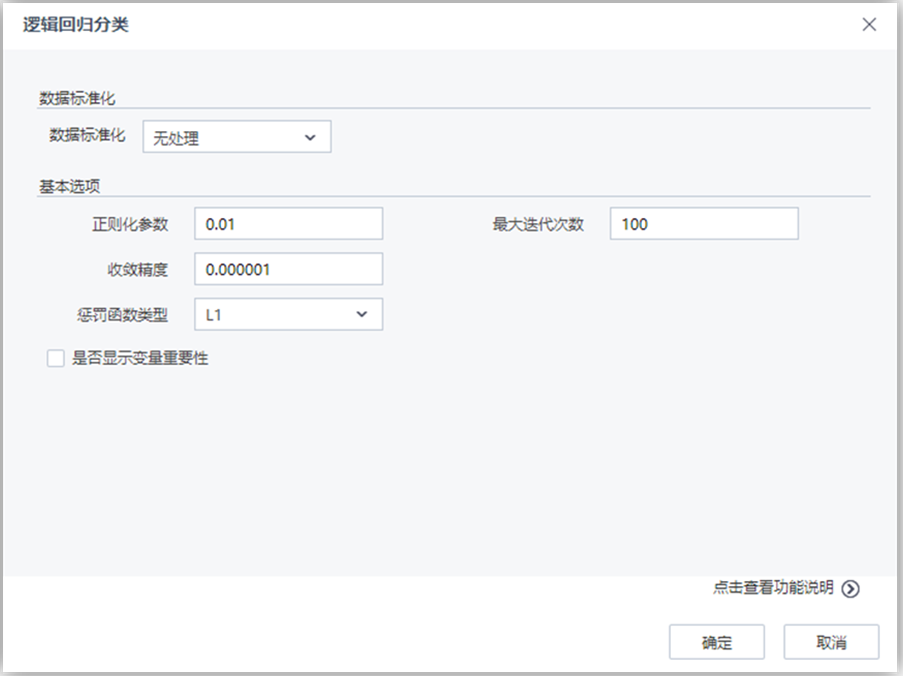
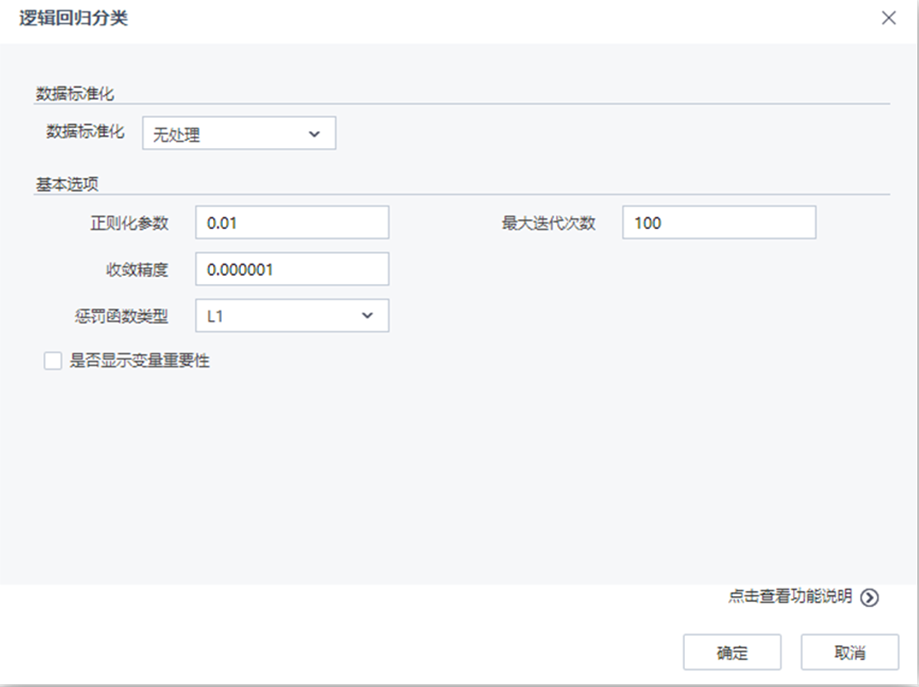
| 参数 | 类型 | 描述 |
| 数据标准化 | 下拉框 | 设置数据标准化的方法,字符型,取值范围:无处理,归一化,标准化,默认值为无处理 |
| 取值区间下限 | 文本框 | 设置归一化取值区间下限,浮点型,取值范围:[0,∞),默认值为0 |
| 取值区间上限 | 文本框 | 设置归一化取值区间上限,浮点型,取值范围:[0,∞),默认值为1 |
| 正则化参数 | 文本框 | 正则化参数控制机器的复杂度,浮点型,取值范围:[0,∞),默认值为0.01 |
| 收敛容差 | 文本框 | 设置终止迭代的误差界,浮点型,取值范围:[0,∞),默认值为0.000001 |
| 最大迭代次数 | 文本框 | 设置最大迭代次数,整型,取值范围:[1,∞),默认值为100 |
| 惩罚函数类型 | 下拉框 | 设置惩罚函数类型,0对应L2罚函数,1对应L1罚函数,(0,1)之间对应L1和L2的组合罚函数,浮点型,取值范围:[0,1],默认值为0 |
| 是否显示变量重要性 | 复选框 | 用户选择是否分析每个变量对于分类结果的影响程度,如果选择是,则在洞察中显示参与建模的每个变量对于模型的贡献程度情况 |
全国服务电话:
企业邮箱:tempo@meritdata.com.cn
地址:中国西安 ▪ 雁塔区西三环天谷八路软件新城国家电子商务示范基地六层


 陕公网安备 61019002000171号
陕公网安备 61019002000171号



