




























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台




服务热线
400-608-2558
咨询热线
15502965860-



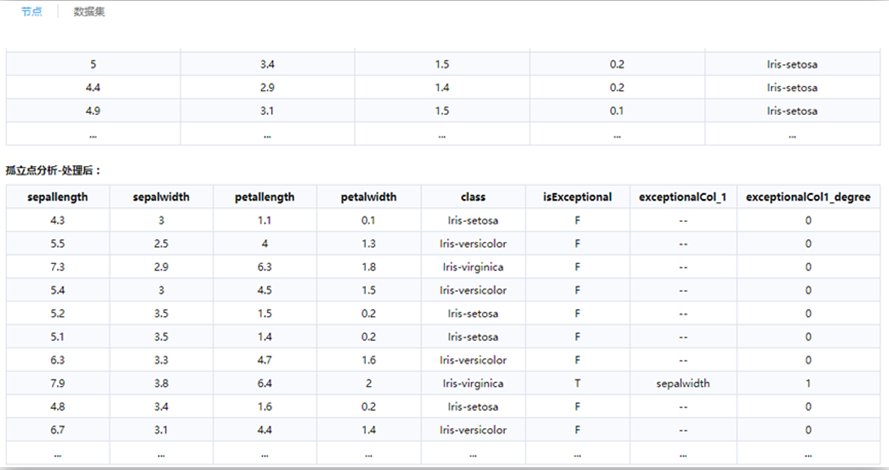
 为每个数值型列的取值范围(即max-min );
为每个数值型列的取值范围(即max-min ); 为各名词列属性的取值个数。
为各名词列属性的取值个数。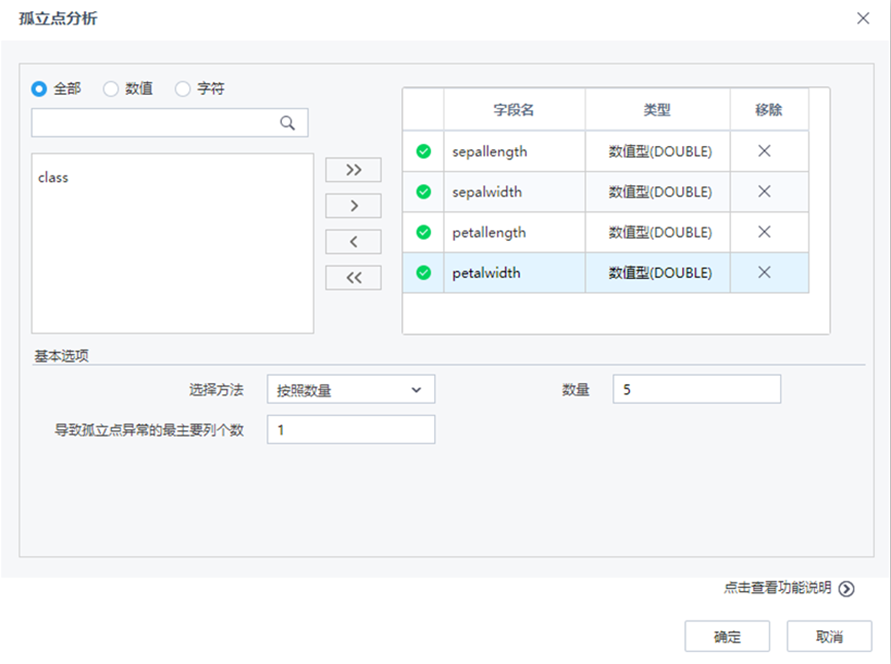
| 参数 | 类型 | 描述 |
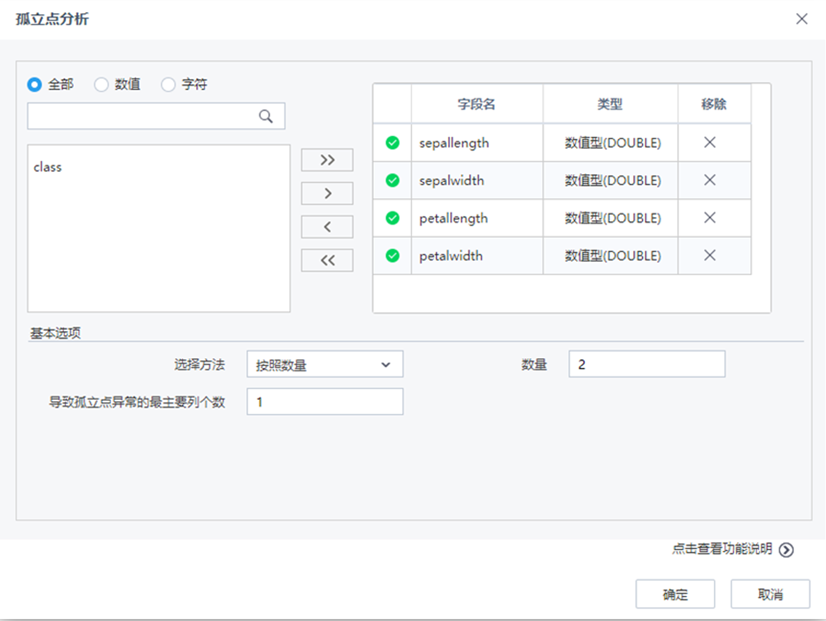
| 选择变量 | 列表框 | 用户指定需要进行孤立点分析的属性列,属性列的数据类型为数值型 |
| 选择方法 | 下拉框 | 提供按照数量和按照比例等方式进行孤立点样本个数筛选。当按比例指定孤立点个数时,需设置比例大小数值。当按数量指定孤立点个数时,需设置数量的具体数值,默认选择按照数量 |
| 数量 | 文本框 | 设置按照数量方式进行孤立点样本筛选的个数,正整数,默认值为5 |
| 比例大小 | 文本框 | 设置按照比例方式进行孤立点样本筛选的比例,正数,取值范围:(0,1],默认值为0.01 |
| 导致孤立点异常的最主要列个数 | 文本框 | 对于多维数据集,算法除了识别出孤立点外,还能够分析每个孤立点异常的列原因。该参数用于指定要分析前多少个导致孤立点异常的主要因素列,正整型,默认值为1。 |
全国服务电话:
企业邮箱:tempo@meritdata.com.cn
地址:中国西安 ▪ 雁塔区西三环天谷八路软件新城国家电子商务示范基地六层


 陕公网安备 61019002000171号
陕公网安备 61019002000171号



