Spark读取kafka复杂嵌套json的最佳实践,与其在大数据分析平台中的应用
2022-09-16 18:54:00
次
随着互联网的更进一步发展,信息浏览、搜索以及电子商务、互联网旅游生活产品等将生活中的流通环节在线化,对于实时性的要求进一步提升,而信息的交互和沟通正在从点对点往信息链甚至信息网的方向发展,这样必然带来数据各个维度的交叉关联,数据爆炸也不可避免,因此流式处理应运而生,解决实时框架问题,助力大数据分析。
kafka是一个高性能的流式消息队列,适用于大数据场景下的消息传输、消息处理和消息存储,kafka可靠的传递能力让它成为流式处理系统完美的数据来源,很多基于kafka构建的流式处理系统都将kafka作为唯一可靠的数据来源。如Apache Storm、 Apache Spark Streaming 、Apache Flink 、Apache Samza 等。
json是kafka消息中比较常见的格式,对于单层json数据的读取和解析相对简单,但是在真实kafka流程处理的业务中,很多情况下都是json嵌套复杂格式消息。Spark1.1以后的版本存在一些实用的 SparkSQL函数,帮助解决复杂的json数据格式,实用函数包括get_json_object、from_json和explode等。
01、Spark框架中的基本概念和内置函数
▶ RDD:Spark的基本计算单元,它是一个弹性可复原的分布式数据集。
▶ Dataframe:定义为指定到列的数据集(Dataset)。DFS类似于关系型数据库中的表或者像R/Python 中的Dataframe ,可以说是一个具有良好优化技术的关系表。
▶ Spark SQL:它是Spark的其中一个模块,用于结构化数据处理,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息,Spark SQL会使用这些额外的信息来执行额外的优化。
▶ from_json:Spark SQL内置的函数,从一个json 字符串中按照指定的schema格式抽取出来作为DataFrame的列,第一个参数为列名,以$"column_name"表示,第二个参数为定义的数据结构
▶ get_json_object:Spark SQL内置的函数,从一个json字符串中根据指定的json路径抽取一个json对象,第一个参数为column名,用$"column_name"表示,第二个参数为要取的json字段名,"$.字段名"表示。
▶ explode:Spark SQL内置的函数,可以从规定的Array或者Map中使用每一个元素创建一列,主要用于数组数据的展开,参数为column名,用$"column_name"表示。
02、Kafka复杂嵌套json解析
1)什么是复杂json?
json是一种轻量级的数据交换标准,具体以逗号分隔的key:value键值对的串形式,主要表现形式包括两种:{对象},[数组],其中key以字符串表达,value包括字符串、数值、boolean值、对象和数组(可嵌套)。在复杂的json数据格式中,通常json数据会有嵌套,每个层级的结构不完全相同,value中不同类型进行混合使用。
下图为一份简单json格式数据:
期望处理的结果为下图的二维表,json串中的key(id,sepallength,sepalwidth,
petallength,petalwidth,label)作为二维表的列,value作为表的一行数据。
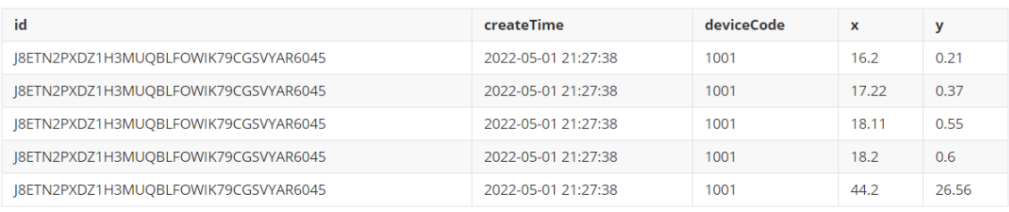
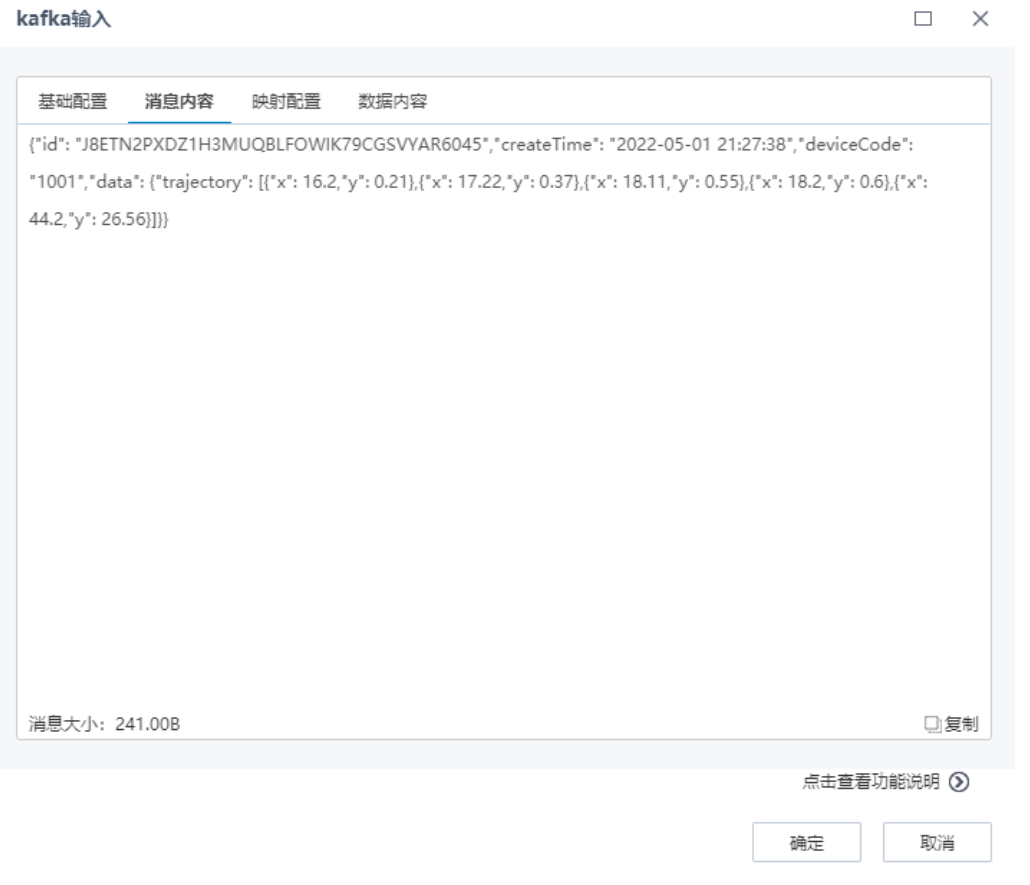
下图为一份复杂json格式数据:
期望处理的结果为下图的二维表,json串中单层key(id,createTime,deviceCode)和需要展开的数组trajectory中单个元素key(x,y)作为二维表的列,value是将数组trajectory中所有的元素展开成多行后,与其他列的数据进行对齐。
2)整体思路
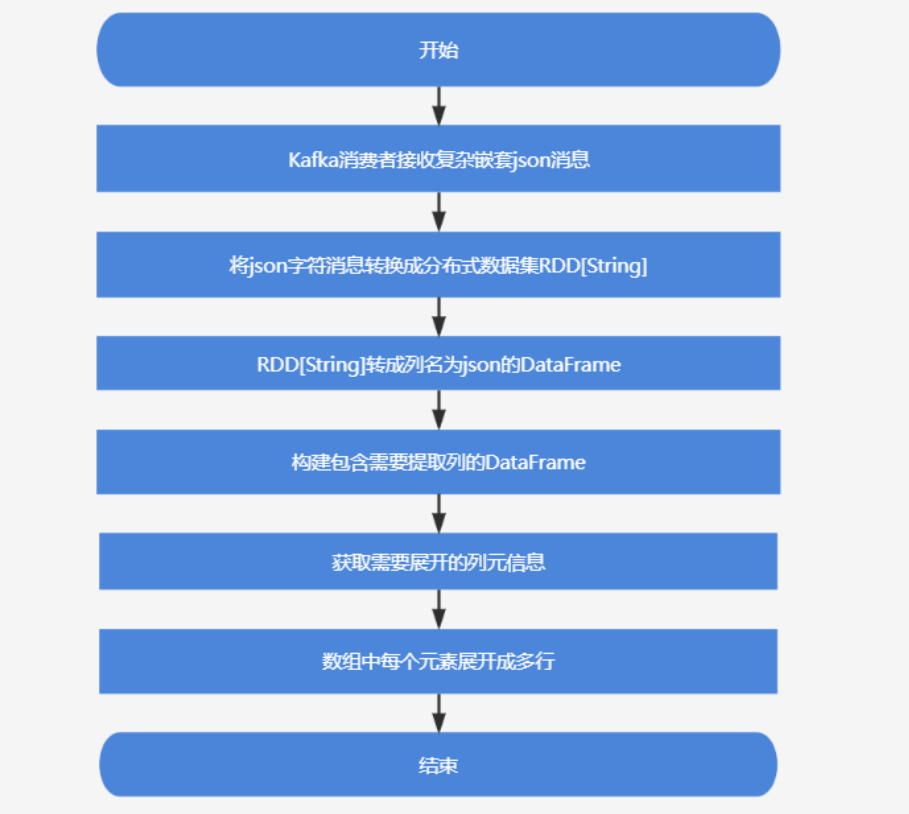
Kafka消费者收到复杂嵌套json消息后,一共有两步。
第一步:首先把这批json字符消息转换成分布式数据集RDD[String]中,再将RDD[String]转换成列名为`json`的DataFrame,然后通过Spark SQL内置函数get_json_object将json对象中的`id`、`createTime`、`deviceCode`、`data.trajectory`分别生成新列,并构建一个包含这些列的新DataFrame;
第二步:获取需要展开的列`data.trajectory`的schema(元数据信息),然后由SparkSQL内置函数from_json将列`data.trajectory`的字符内容转换成数组对象,最后通过SparkSQL内置函数explode将`data.trajectory`中的数组中每个元素展开成多行。
基于spark解析复杂json流程设计图:
3)Spark读取kafka复杂json消息解析核心代码
json格式数据如果使用现有的工具,用户常常需要开发出复杂的程序来读写分析系统中的json数据,Spark SQL对json数据的支持是从1.1版本开始发布,并且在Spark 1.2版本中进行了加强。
下图的代码是通过Spark SQL内置的json函数将复杂json转换成一张二维表,并支持将json中数组数据进行展开处理。
4)kafka复杂json解析在Tempo AI中的应用
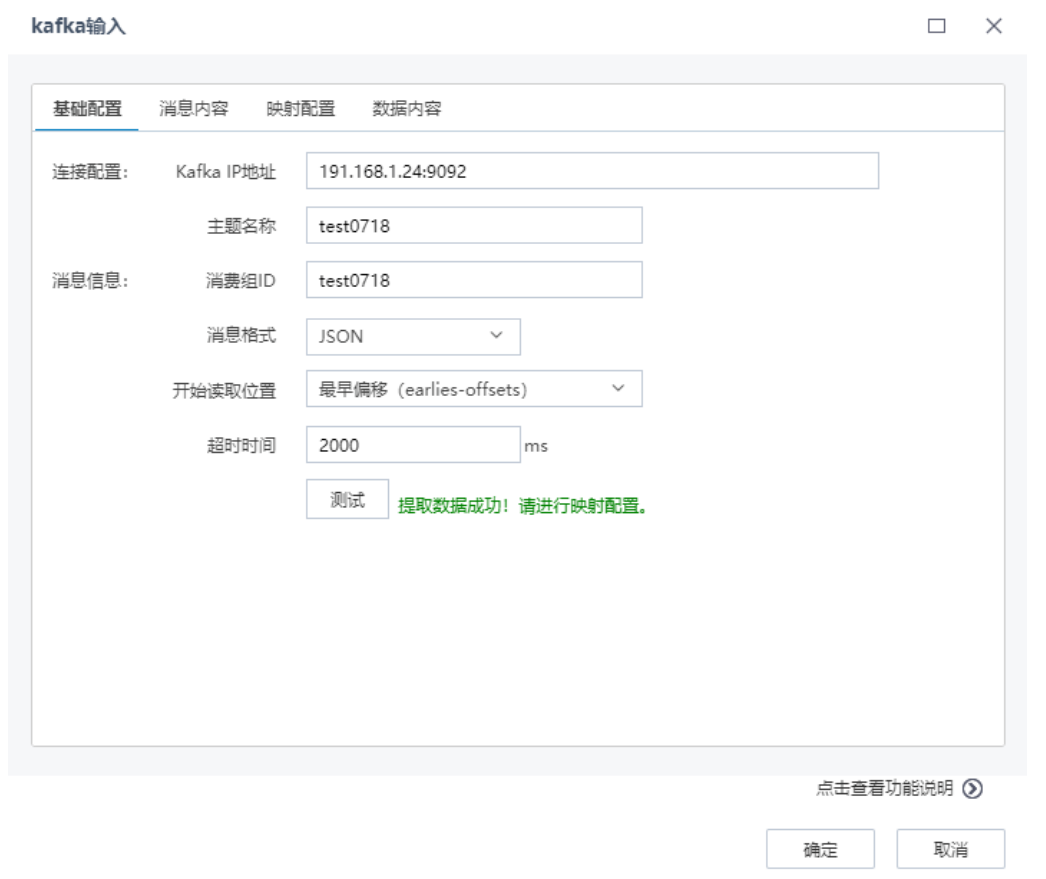
Tempo AI机器学习平台将kafka数据作为数据挖掘分析标准数据源,既支持简单的json解析,也支持复杂json解析,先进行基础配置读取消息数据,查看消息内容,然后进行映射配置,将数据内容与对应元信息进行匹配,最后可以预览数据内容。
基础配置,包括连接配置和消息信息配置,如下图所示:
在“消息内容”页面,查看提取的单条Kafka消息内容,如下图:
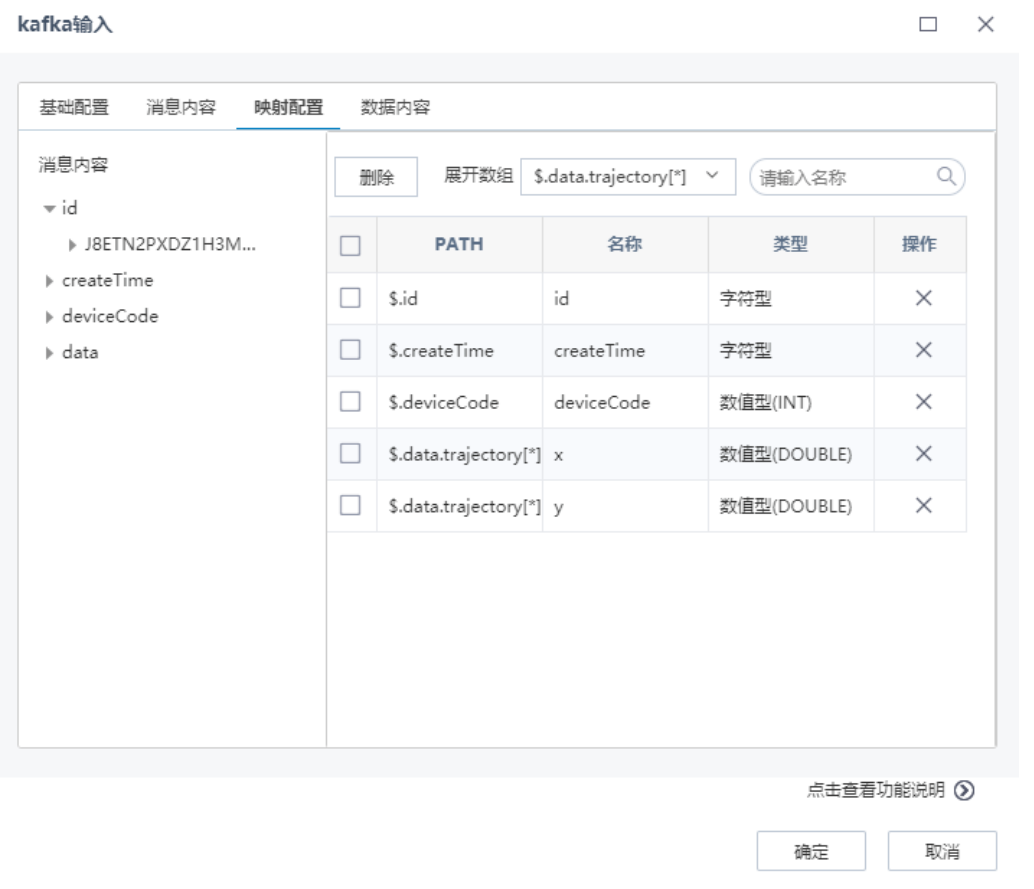
在“映射配置”页面,根据左侧预览的消息内容,通过点击选择左侧的消息到右侧,进行映射配置,可以设置需要展开的数组,如下图:
kafka输入节点配置完成后,执行AI流程,查看洞察信息,如下图所示:
综上,json是一种轻量级的数据交换格式,易于阅读和编写,目前是一种主流的数据格式,json字符串作为消息在kafka消息流中传递应用很广泛,通过Tempo 机器学习平台封装的Spark SQL解析复杂json的能力,极大简化了使用json数据的终端的相关工作,使客户更专注于自己的业务。





























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台
















 陕公网安备 61019002000171号
陕公网安备 61019002000171号



