




























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台




服务热线
400-608-2558
咨询热线
15502965860-



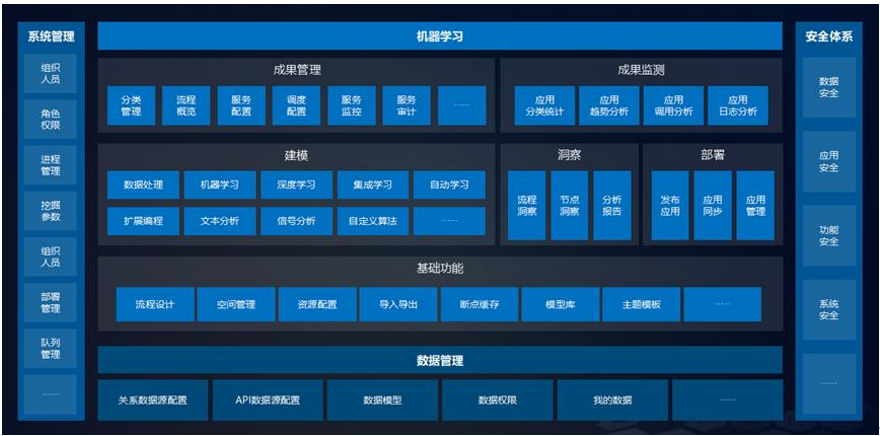
| 算法类型 | 功能节点 | 说明 |
| 数据预处理 | 提供对数据进行预处理功能,包括对数据的清洗、转换、归约、集成等,以便提高分析数据的质量。 | 行:数据过滤、排序、随机抽样、数据平衡、数据去重; 列:设置角色、重命名、属性过滤、随机数/ID生成、缺失值处理、数值型属性变换、字符型属性变换、日期型属性变换; 高级:表转置、 分类汇总、数据标准化、数据平滑、孤立点分析、RFM、季节解构、异常值检测、自动数据处理、堆叠列、过程查询分析器; 融合:数据连接、数据追加、数据拆分、数据分解、数据差集; 特征工程:属性生成、主成分分析、因子分析、奇异值分解、分箱、变量选择、自动特征、WOE编码、数据分组、特征编码、高级特征交叉。 |
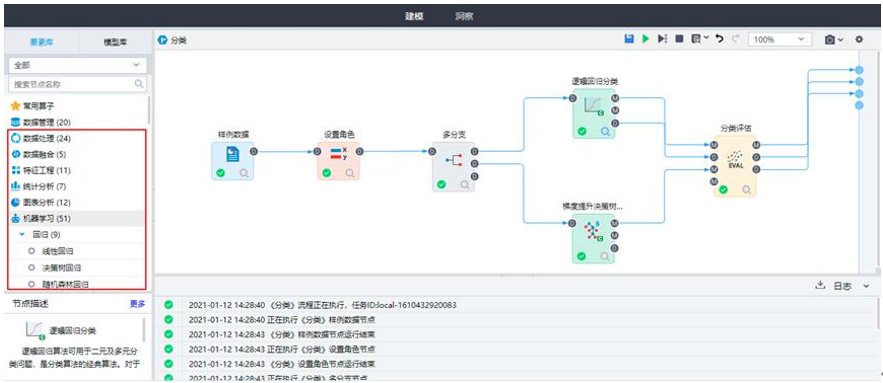
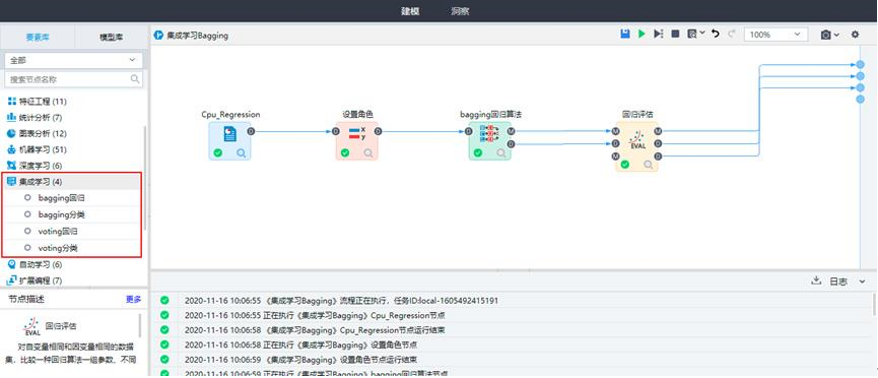
| 分类 | 分类属于预测任务,就是通过已有数据集(训练集)的学习,得到一个目标函数f(模型),把每个属性集x映射到目标属性y(类),且y必须是离散的。 | 逻辑回归分类、朴素贝叶斯、Xgboost分类、贝叶斯网络分类、BP神经网络分类、随机森林分类、支持向量机分类、 CART、ID3分类、C45+决策树分类、梯度提升决策树分类、L1/2稀疏迭代分类、RBF神经网络分类、KNN、线性判别分类、Adaboost分类、Bagging分类、DNN分类。 |
| 回归 | 回归是最常用的数值预测方法,它是在分析现象自变量和因变量之间相关关系的基础上,建立变量之间的回归方程,并将回归方程作为预测模型,根据自变量在预测期的数量变化来预测因变量的值。 | 线性回归、决策树回归、SVM回归、梯度提升树回归、BP神经网络回归、保序回归、曲线回归、随机森林回归、L1/2稀疏迭代回归、Bagging回归、DNN回归、LSTM回归。 |
| 聚类 | 聚类分析仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组。其目标是,组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。 | KMeans、模糊C均值、EM聚类、Hierarchy、Kohonen聚类、视觉聚类、Canopy、幂迭代。 |
| 关联规则 | 关联规则,指在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。 | Apriori、FPGrowth、序列。 |
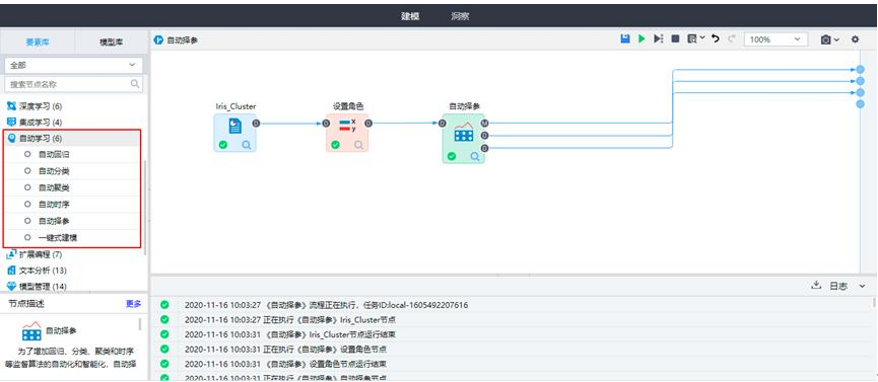
| 时间序列 | 时间序列通常是按时间顺序排列的一系列被观测数据(信息),其观测值按固定的时间间隔采样。研究人员作预测时,常以过去的历史资料为依据,预测将来的变化。 | ARIMA、稀疏时间序列、指数平滑、移动平均、向量自回归、X11、X12、回声状态网络、灰色预测。 |
| 综合评价 | 使用比较系统的、规范的方法对于多个指标、多个单位同时进行评价的方法,称为综合评价方法 | 熵值法、TOPSIS、层次分析法、模糊综合评价法。 |
| 推荐 | 推荐是根据用户兴趣和行为特点,向用户推荐所需的信息或商品,帮助用户在海量信息中快速发现真正所需的商品。 | 协同过滤。 |
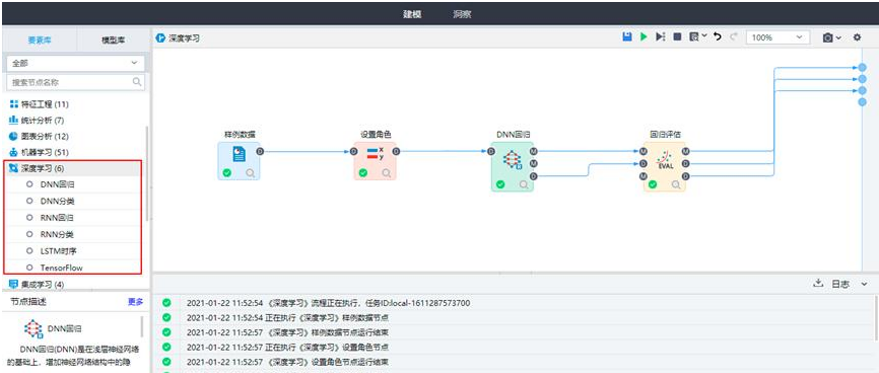
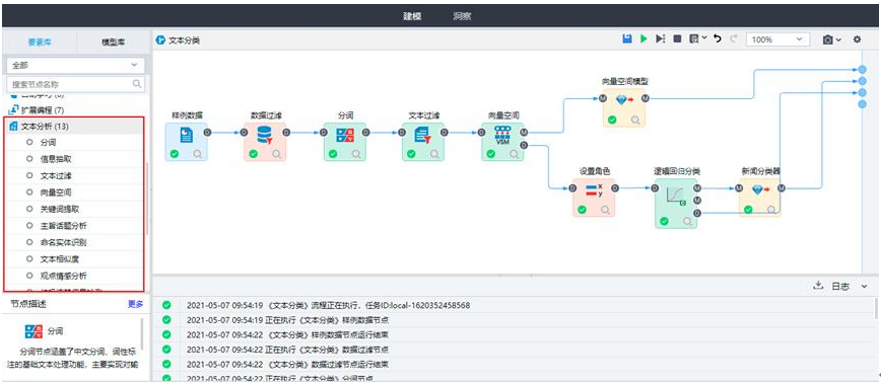
| 文本挖掘 | 文本挖掘是指从大量文本数据中抽取事先未知的、可理解的、最终可用的知识的过程,同时运用这些知识更好地组织信息以便将来参考。 | 分词、信息抽取、文本过滤、向量空间、关键词提取、主旨话题分析、观点情感分析、垃圾违禁信息检测、文本相似度、命名实体识别、文本摘要、词频统计、主题模型合并。 |
| 统计分析 | 提供统计分析方法,对通过调查获取的各种数据及资料进行数理统计和分析,形成定性和定量的结论。 | 方差分析、相关系数、典型相关分析、偏向相关分析、相似度、描述数据特征、概率单位回归。 |
全国服务电话:
企业邮箱:tempo@meritdata.com.cn
地址:中国西安 ▪ 雁塔区西三环天谷八路软件新城国家电子商务示范基地六层


 陕公网安备 61019002000171号
陕公网安备 61019002000171号



