由于Spark在使用JDBC方式读取关系型模型数据的时候,默认采用单线程任务执行。在数据量较大时,经常发现内存溢出、性能低的问题。在扩大内存读取后进行重分区,又会消耗时间,浪费资源。
因此,开发并发读取关系型模型数据,可以有效提高任务处理并发度,减少单个任务的数据处理量,进而提升处理效率。
分布式并发处理优化
(一)总体思路
关系型模型并发读取首先要选取分区字段,按照字段类型和分区个数确定并发分区间隔的key值。假设key值可以将模型数据均匀划分成多个逻辑分区,根据key值构成查询条件将模型数据进行并发读取。其中的关键点包括:
1、分区字段的选取规则
(a)初步确定模型中第一个字符或者数值型字段。
2、分区个数
(a)给出默认分区个数,测试读写后按照1000w数据量给出建议的资源配比和默认分区个数。
(b)允许用户进行自定义配置。
3、静态分区策略
(a)数值型:转换成字符并逆序,按照数值位取值的字符范围和分区个数确定并发分区间隔的key值,进行多分区构造。
(b)字符型:逆序后按照单字符取值范围和分区个数确定并发分区间隔的key值,进行多分区构造。
(二)总体处理流程
总体处理流程如图所示:
分区个数合法校验及处理规则:分区个数合法校验及处理规则为分区个数必须在[1,range]范围内,超出下限按照一个分区处理,超出上限按照上限range处理。支持的最大分区个数(range)字符型为64的4次方,数值型为10000。
(三)阈值范围并发读取
阈值范围并发读取适合分区字段为数值类型的模型。
关键参数:
partitionColumn:分区字段名称
lowerBound:取值下限
upperBound:取值上限
numPartitions:分区个数
(四)默认并发读取
默认并发读取适应于字符和数值类型的分区字段,按照类型的取值范围获取近似均分的过滤条件,将数据按照条件分配到不同的逻辑分区中,并以并发执行来提升数据读取效率。
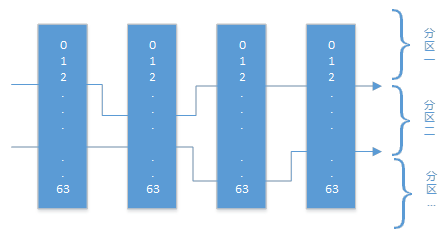
1、模型并发读取
模型并发读取设计按照分区个数不同采用不同的接口调用方式。
►分区个数为1
val url = "jdbc:mysql://host:3306/test"
val prop = new java.util.Properties
prop.setProperty("user", "***")
prop.setProperty("password", "***")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
val df = spark.sqlContext.read.jdbc(url,"tname",prop)
url为数据库连接串信息。
tname为查询的表名,也支持查询条件,形如:
(select * from ronghe_mysql_bigint_50wwhere cast(RY_YGGH as UNSIGNED) > 250000)tmp
prop为数据库连接信息、用户名、密码、driver等配置信息。
►分区个数大于1
val url = "jdbc:mysql://host:3306/test"
val prop = new java.util.Properties
prop.setProperty("user", "***")
prop.setProperty("password", "***")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
val df = spark.sqlContext.read.jdbc(url,"tname",predicates,prop)
多分区并发读取比分区个数为1的参数增加了分区预划分条件。
其中,predicates为分区预划分条件,Array[String],读取时按照每个元素内容过滤数据。
2、分区预划分条件
分区预划分条件是由多个条件构成的字符串数据。
val predicates = Array[String](
" cols < '3'",
" cols >= '3' and cols <'6'",
" cols >= '6'
)
分区预划分条件包括分区条件列和比对值。分区条件值由选取的分区字段及其操作构成,比对值即为静态分区间隔值。考虑到有序数值型、字符型在业务场景中使用一般高位相似低位差异明显,因此对分区字段进行逆序处理。
假设分区字段为splitCol。
splitCol为数值类型时:分区条件列cols 为reverse(cast(splitColas char))。
splitCol为字符类型时:分区条件列cols 为reverse(splitCol)。
假设分区间隔值为splitKeys(Array[String]),长度为L。对比值按照左闭右开的方式构造。
第一个条件为cols < splitKeys(0);
第二个条件为cols >= splitKeys(0) and cols < splitKeys(1);
第i个条件为cols >= splitKeys(i-2)and cols < splitKeys(i-1);
最后一个条件为cols >= splitKeys(L-1)。
3、分区个数
模型并发读取设计,按照四位字符来表示分区间隔值。那么,可表示的值范围即为每位可取的值个数的四次方。
设定字符每位可取64个,数字可取的值个数10,即支持的最大分区个数(range):字符型(64的4次方)、数值型(10000)。
4、静态分区间隔值获取
实现思路
按照字段类型的字符范围找到分区间隔值,即找到间隔值所表示范围的近似均分位置点。
假定分区间隔值使用四位字符表示。(设N个分区)
数字类型字符间隔值寻找思路:
(1)数字取值[0,9](暂不考虑小数点,按位将被分到小于0对应的分区),表示范围:1, 2, 3,……,9998,9999。
(2)找到每个分片的大小范围S,表示范围个数除以分区个数(10^4/(N-1))。
(3)S-1,2S-1,3S-1,……,(N-1)*S-1即为可以将四位数均分的间隔值。
字符类型间隔值寻找思路(取值范围64个字符,优化算法):
(1)按照常用程度,将间隔值每位字符取值范围确定为:Array('.', '0', '1', '2', '3','4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J','K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z','a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p','q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '~')
(2)不常用字符将被归到最临近的一个分区,中文字符将被归到最后一个分区,避免不常用字符的独占一个分区情况,以减少对资源的消耗。
(3)找到每个分段的大小范围S,表示范围个数除以分区个数(64^4/(N-1))
(4)同数字字符间隔值,将字符间隔值理解成64进制的数字(可以采用移位运算快速获取),那么S-1,2S-1,3S-1,……,(N-1)*S-1就是将四位字符近似均分的数字,每位对应的字符间隔值数组中的字符构成的字符串即为间隔值。
for (j <- 1 to digitsNum) {
tmp(digitsNum - j) = charactors(keyInt & (charLength - 1))
keyInt >>= 6
}
字符类型间隔值寻找思路(取值范围任意个字符,通用算法):
与字符类型字符间隔值总体寻找思路一致,但不受取值范围个数的限制。
(1)按照常用程度,将间隔值每位字符取值范围确定为Array(……),元素个数为m。
(2)不常用字符将被归到最临近的一个分区,中文字符将被归到最后一个分区,避免不常用字符的独占一个分区情况,以减少对资源的消耗。
(3)找到每个分段的大小范围S,表示范围个数除以分区个数(m^4/(N-1))。
(4)同数字字符间隔值,将字符间隔值理解成m进制的数字,那么S-1,2S-1,3S-1,……,(N-1)*S-1就是将四位字符近似均分的数字,这些数字对应的字符串即为均分字符范围的间隔值(数字每一位对应的字符间隔值数组中的字符构成的字符串即为间隔值)。
十进制转为m进制,以十进制数keyInt为例,tmp为转换后结果数组:digitsNum为表示位数4。
for (j <- 1 to digitsNum) {
tmp(digitsNum - j) = charactors(keyInt % m)
keyInt = math.floor(keyInt / m).toInt
}
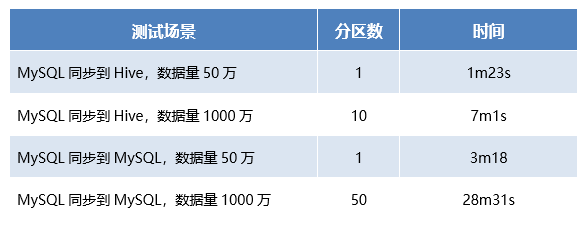
测试结果
在数据资产平台中,以50万、1000万的数据进行同步性能测试,测试结果如下表:
总结与展望
按照分区字段并发读取数据进行处理能够有效提升数据的处理能力,但受分区字段取值范围、数据分布情况的影响,效果不尽相同,后续将对分区策略进行持续优化,以达到适应各种业务场景的性能要求。





























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台





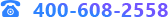



 陕公网安备 61019002000171号
陕公网安备 61019002000171号



