美林数据技术专家团队 | 金融行业图计算平台构建相关实践
2021-09-02 10:57:30
次
引言
随着信息技术的迅猛发展及企业数字化转型,快速积累了大量的数据,其中关系类数据如社交数据、电商数据等呈指数级增长。图结构数据在各个场景中也得到越来越多的应用,包括社交网络、推荐搜索、知识图谱、医药研发、量子物理等。在探索这些“关系数据”过程中,其相对基于传统结构化数据的方法显现出了巨大优势,图数据存储及图算法等也得到了迅猛的发展。
图结构数据的火热应用快速扩展到各个领域,其中金融领域为进一步增强智能风控管理能力,更好地支撑信贷等业务的发展,也陆续开展基于图数据的模型建设研究。
目前,常规的基于结构化数据的分析方法首先对数据进行特征分析,构建特征工程,然后选取指标搭建相应的分类模型。这种方法没有考虑数据之间的关联性,如“同地址”、“同电话”的客户相互影响很大,而把这种“相互影响”考虑进行建模过程,对模型性能提升会有较大影响。
同时,银行现有的图谱数据通常是非常直接的关联。如两个人之间是夫妻关系,这对于基础的连通图、社区发现等依赖于构图的图算法有较大影响。需要我们去丰富构图的方法,建立节点与节点之间的隐性关联。
为了充分利用现有结构化属性数据及图谱数据,在构建图计算平台时,既加入了传统的出入度、簇系数、介数等中心性指标,也做图的表征学习,考虑节点和边关系的属性信息,以进行更好的信息融合。
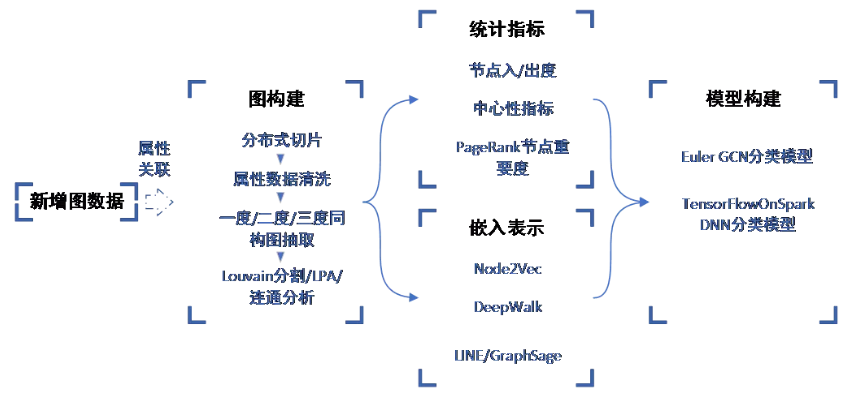
一、整体架构
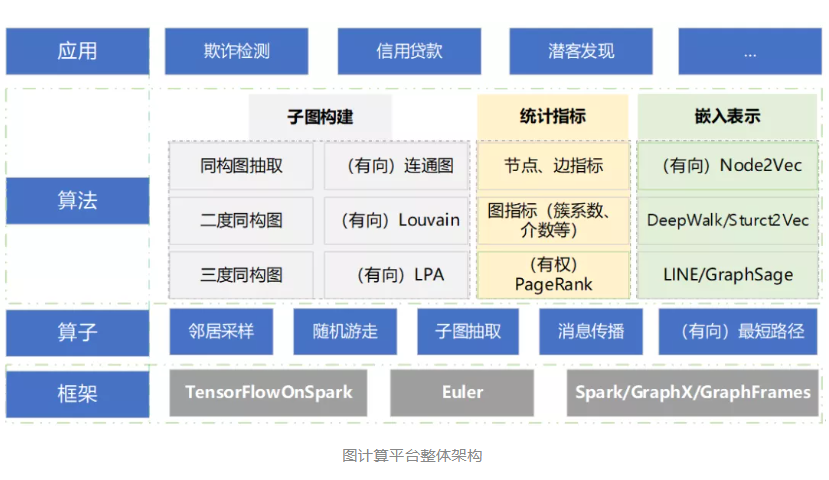
算子层是图计算常用的操作,包括邻居采样、随机游走、消息传播、最短路径等。
算子之上是图算法层。由于现有图数据为很大的异构图,需要通过同构图抽取、louvain分割算法等进行子图构建,且由于业务规则,抽取的图为有向图。这部分需要对现有的算法进行改造,以支撑该场景。同时会对抽取的子图提取节点度、簇系数、介数等统计指标。嵌入表示方面,有基于拓扑结构的Node2Vec/Struct2vec及基于采样的LINE/GraphSage等算法。
图平台应用主要是风控,常见的应用场景有欺诈检测、信用贷款、潜客发现等。
二、算法改造
由于业务的特殊性,图数据间关系均为有向连接,且带有权重,就需要我们基于Spark实现对应的算法,包括有向最短路径、二度/三度同构图、有向连通图、有向Louvain算法、有向LPA算法和有向Node2Vec算法。
以Louvain分割算法为例,简述算法的改造过程。
Louvain算法是基于模块度的图分割算法,能够发现层次性的社区结构,其优化目标为最大化整个子图的模块度,其改造难点在于模块度的改造及并行化实现。
模块度是评估一个图划分好坏的度量方法,它的物理含义是子图内节点的连边数与随机情况下的边数之差,其定义如下:
其中,Aij表示节点i和节点j之间的权重,当网络不带权重时,可看做为1;Ki=∑jAij表示所有与节点i相连的边的权重之和(度数);Ci表示节点i所属的子图;m=0.5*∑ijAij表示所有边的权重之和(边的数目)。∑in表示子图c内的边的权重之和,∑tot表示与子图c内的节点相连的边的权重之和。基于模块度的社区发现算法,都是以最大化模块度为Q目标。
对于有向模块度,具体参考《Directed Louvain : maximizing modularity in directed network》。基本思想为:如果两个顶点u和v,u具有小的进度、大的出度,v有小的出度、大的进度,则存在从u到v的连接概率应大于从v连向u的概率。可定义出有向图的(Leich and Newman)模块度为:
其中Aij表示存在i到j的边,diin,djout分别表示入度和出度。进而模块度的变化量可写为:
其中,∑totin(resp.∑totout)表示连接子图C的入度(出度)。
由于原始算法是逐个选择节点,重新计算它的子图,不断进行迭代。这种串行化的计算方式,对分布式计算框架非常不友好。因为在选择一个节点进行计算时,其它的节点是不能进行变化的。
这种方式不能进行并行化计算,也不能充分利用分布式框架的高并发、集群计算优势。
为了使算法能够运行在集群环境上,需要对算法进行并行化改造。如在每轮迭代中同步更新多个节点的信息,即根据t-1轮中邻居节点的信息来更新t轮中节点的信息。但这样会造成“消息滞后”,造成“子图互换”问题。因此,需要进行后处理。基于算法结果,求解连通区域,将同一个连通区域的点都归为一个子图。
三、建模流程
基于图计算平台的数据建模流程大致可分为以下四个步骤:
1、图构建:结合图计算平台能力,实现同构子图的获取。首先结合分布式切片策略将数据加载到Spark中,然后借助Spark实现属性数据的清洗。如缺失值填充、孤立点处理等。然后结合消息传播实现一度、二度、三度同构图的获取,并采用Louvain分割算法、LPA算法、连通分析算法得到最终的同构子图。
2、图特征:结合图计算平台能力,获取各节点特征表示。特征包含基于节点度、中心性等的统计特征,还包括基于Node2Vec、LINE、GraphSage的嵌入表示特征,并将两者进行拼接,同时对于同一节点在不同子图中的特征,也进行拼接,进而获得节点的最终特征表示。
3、图模型:结合具体的业务场景,构建图模型。具体可借助Euler建模平台,构建GCN等图分类模型,也可借助TensorFlowOnSpark框架,实现基于TensorFlow和Spark的分布式深度学习模型构建。
4、新图关联:对于新增客户,所构成的异构子图。根据其属性相关性(相似或相同),和已有的异构图数据进行关联,然后进行后续处理,处理流程同1、2、3步。
四、场景示例
以“潜客发现”场景为例,通过对用户的历史数据进行分析,提取不同维度的信息,对客户意愿进行预测,以达到发掘潜在客户的目的。其关键在于通过模型算法挖掘出数据中所隐含的用户行为规律。传统的方法不能对用户各行为及用户间各关系进行建模,通常具有较低的召回率。
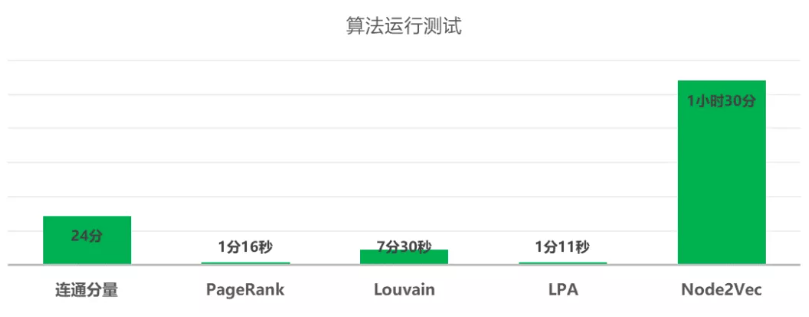
故结合上述建模流程,探索图计算在“潜客发现”场景的效果。具体数据实体(节点)有手机号、地址、邮箱等,关系有亲属关系、交易关系等,属性有姓名、性别、年龄等,按照上述流程对有154万节点、917万条边及34个属性的图数据进行处理,构建相关特征,各算子运行效率如下:
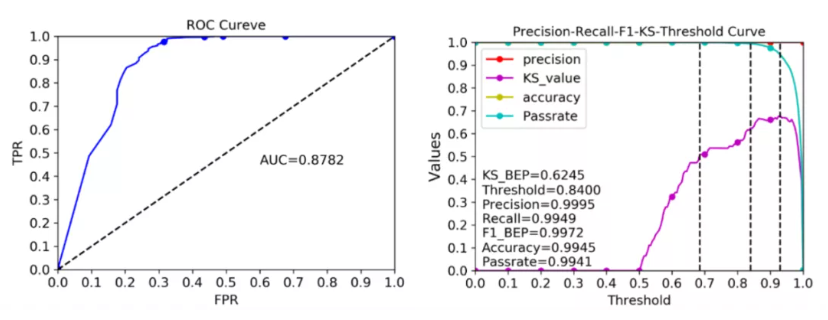
最终,对于具有1亿节点、15亿条表的图数据,提取特征后构建分类模型。其效果如下图所示:
可以看出,基于图数据的建模方式可以获得更高的精度和召回率,对于金融机构在发掘潜在价值客户的精准度有较明显的提升,从而更好的支撑“潜客发现”的业务开展。
借助分布式计算和图计算,可以对大规模的图数据进行处理,在结构化数据的基础上融合“关系数据”,建立出性能更好的模型。在金融系统的欺诈检测、信用贷款、潜客发现等应用场景都能得到广泛的应用,实现金融企业智能风控管理能力的有效提升。
近年来,随着人工智能、大数据等新技术的深入应用,为金融机构的业务开展带来了革命性的变革。美林数据依托领先的数据价值挖掘技术与能力,为银行、保险、证券、基金等金融机构提供专业的数据治理、数据分析与挖掘等数字化技术服务,助力提升金融机构的风控管理、市场营销等业务能力,利用金融科技助推我国金融市场的繁荣发展。





























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台





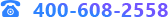

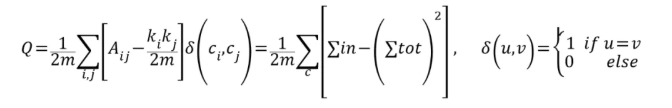
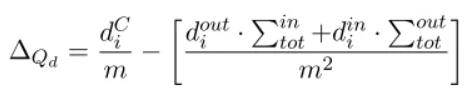


 陕公网安备 61019002000171号
陕公网安备 61019002000171号



