美林数据技术专家团队 | 集团系统数据检索中相关内容推荐的应用
2021-08-17 09:20:00
次
某集团公司通过近几年的信息化建设,已经基本完成了信息化的全业务覆盖,初步实现了数据的集中存储,数据存储总量40T,数据条数增长量1494万/月,数据存储增长1T/月,其中有30%的数据是以文件的形式存储。
文件作为业务活动的过程记录和结果沉淀,对于业务流程贯通、业务知识沉淀,具有非常重要的意义。该集团公司的数据虽然已经实现集中存储,但是数据仍然按业务条线、按系统方式存储、管理、利用,且文件数据具有非结构化的特点,因此对于文件数据的利用效率很低。具体体现在:
01、集中管理后的价值充分展现,业务流转过程中跨业务的数据获取难。
02、缺乏对现有非结构化文件数据的管理和检索,导致了“人找数据难”的局面。
03、虽然已经有了海量的文件数据,但这些数据并未形成知识加以沉淀。
面对目前存在的问题,通过公司领导层的协调推动,梳理了各业务部门的具体业务数据和业务需求,设计了非结构化文档一体化管理平台,在平台实现过程中,通过自然语言处理、机器学习、人工智能等技术,对用户获取文件数据的检索、浏览过程进行分析,向用户主动推送相关内容,将“人找数据”转化为“数据找人”。
一、业务需求和问题定义
1 相关搜索
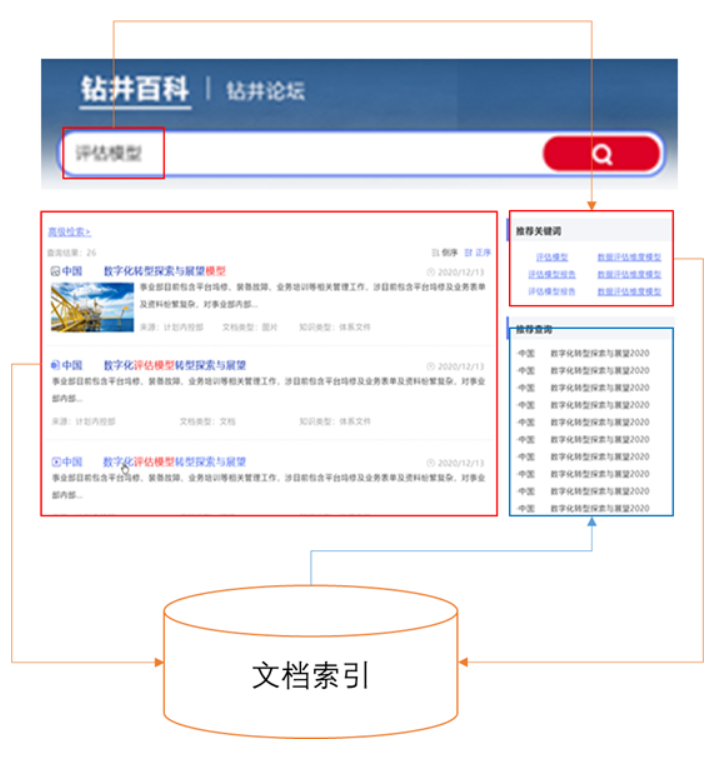
当用户在搜索框中输入检索内容时,在右侧推荐与检索内容相关的关键词,并在推荐查询栏给出相关的查询结果。
2 相关文档
当用户浏览文档时,根据当前文档内容,在右侧推荐内容相关的文档。

从信息获取的角度来看,搜索和推荐是用户获取信息的两种主要手段。
搜索是用户主动获取信息的行为,用户根据将自己的诉求用词语、短语、句子的形式表达出来,输入到搜索引擎中获取检索结果,用户通过浏览和点击检索结果来判断诉求是否得到满足。可以看出,在应用搜索时,用户的需求是比较明确的。
推荐是用户被动接收信息的行为,推荐系统根据收集的用户行为特征,结合历史积累的数据,采用某种算法得到用户可能感兴趣的信息,并发送给用户。因此,推荐对应的是用户模糊而不明确的需求。
目前主流的搜索引擎仍然是以文字构成查询词query,因为文字是描述需求最简洁、最直接的方式,搜索引擎抓取和索引的绝大部分内容也是以文字方式组织的,在大多数搜索查询中,用户都是使用较短的query,一个query一般不会超过5个元素,通过搜索查询很难描述用户复杂的、潜在需求。
例如“公司最近下发的、与我日常工作相关的文件有哪些?”,“我正在浏览的文件相关的文件中,有哪些大家比较关注?”
几乎没有用户愿意输入这么多字来找结果,同时搜索引擎对语义的理解目前还无法做到足够深入。因此,这类复杂的、潜在的需求无法通过搜索引擎得到满意的查询结果。所以在满足这些需求的时候,通过推荐系统设置的功能(如:相关推荐、猜你喜欢、浏览过该信息的人还在关注),加上与用户的交互(筛选、排序、点击),不断积累和挖掘用户偏好,可以将这些难以用文字表达的需求良好的满足起来。
在搜索引擎中加入推荐系统,有多种方式,简单的做法可以基于查询query和相关query,结合历史的query和文档的关联数据,使用基于规则和基于内容相结合的方法进行推荐,这种方法就可以满足一般的需求。
三、常用的推荐方法及算法
1 基于机器学习的方法
采用特征工程,提取和衍生出推荐信息(物)的各类特征,同时也提取和衍生出推荐对象(人)的各类特征,应用机器学习算法,训练出推荐模型。
比如要推荐书籍,对书籍本身可以按照类型分(文艺、科学、科幻、小说……),按照长短分(短篇、中篇、长篇……),按照文字图片比分(图为主、文字为主……)等等;而用户按照性别、年龄、所在城市等属性划分。
这种方法的优点是方案简单稳定,缺点是每一个新用户/物品出现的时候都要对其进行贴标签(tagging),然后对于新的属性无能为力,需要人为干预改进。
2 基于内容相似的方法
基于内容相似的推荐,是根据用户过去关注的内容(content),为用户推荐和他过去关注的内容相似的内容。例如,一个推荐书籍的系统可以依据某个用户之前喜欢很多的计算机相关的书籍而为他推荐《机器学习导论》。
基于内容相似的推荐一般包括以下三步:
(1)Content Representation
为每个content抽取出一些特征来表示此content。
(2)Profile Learning
利用一个用户过去关注(及取消关注)的content的特征数据,来学习出此用户的偏好特征(profile)。
(3)Recommendation Generation
通过比较上一步得到的用户profile与候选content的特征,为此用户推荐一组相关性最大的content。
3 基于协同过滤的方法
根据用户对目标信息的喜好程度,找到和目标用户相似的用户,然后将待推荐的信息打分,打分的权重根据与目标用户爱好类似的用户的相关度给出,常见的做法是将用户和信息之间的interaction做成一个矩阵,然后利用矩阵分解(SVD, LatentFactor)得出用户的特征矩阵和信息的特征矩阵。
协同过滤现在是推荐系统比较主流的方法,Yahoo、豆瓣等网站就是采用这种方法。由于是基于用户的推荐,所以对于热门的信息,推荐效果往往比基于内容相似的方法好很多,然而如果用户不足,或者信息很冷门,效果就不太好,也就是说对新加入或小众的信息和用户不能很好的处理。
四、技术实现
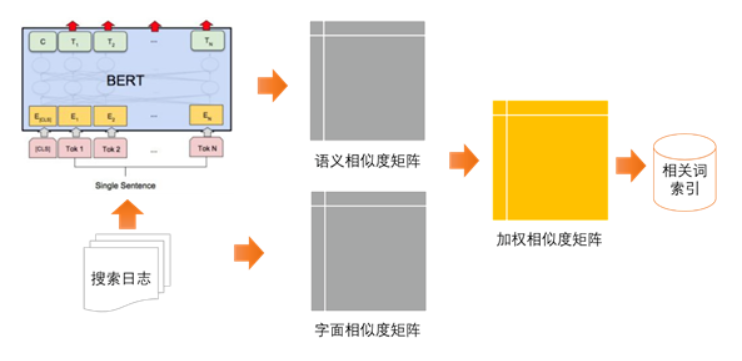
考虑到本系统应用于集团企业内部,使用的用户数有限,不适宜采用基于用户相似的协同过滤。因此在技术实现上,以基于内容相似的推荐方法为主要框架,结合bert语义表达、文本相似算法、余弦夹角算法,实现相关搜索词、相关文档推荐等功能。
1 相关搜索词推荐
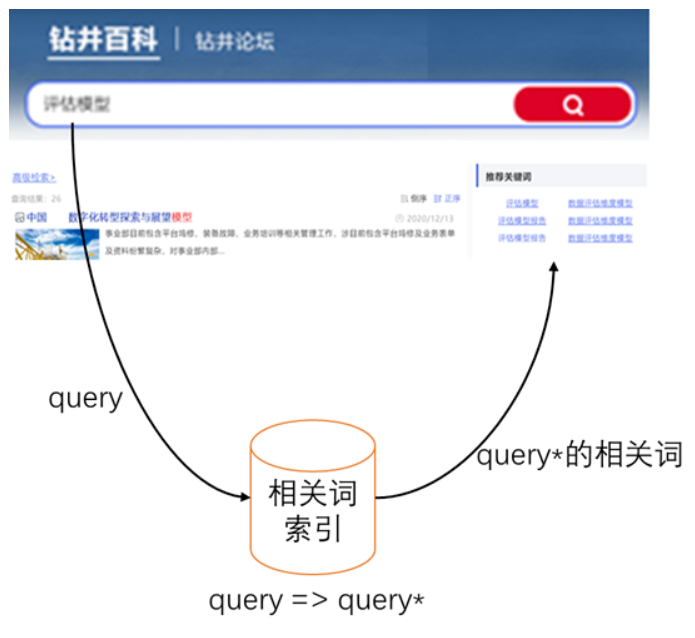
整体框架是构建相关搜索词模型,计算历史搜索词之间的相关性,并将搜索词与最相关的N个词存入ES的相关词索引中,当用户发起检索时,从相关词索引中找到对应的相关词展示出来。
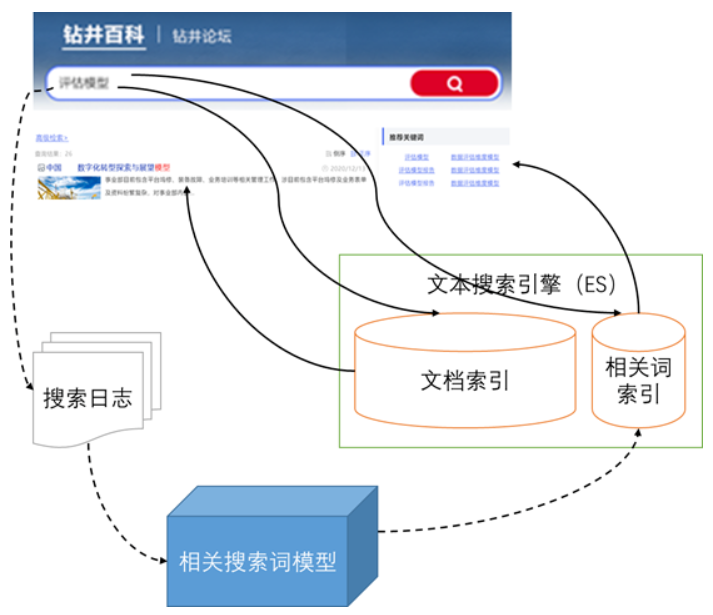
相关搜索词模型每日定时运行,计算当天新产生的搜索词,并更新最近M条搜索词的相关词,计算结果保存在相关词索引中。
(2)相关搜索词的实时展现
当用户发起搜索query时,从相关词索引中得到与query最相似的词query*,将query*的相关词返回展现在页面上。
(3)词典维护
项目需要维护停用词典、自定义词典,用以优化相关词推荐的效果。
停用词典可以过滤掉推荐结果中需要屏蔽的词。
自定义词典示例:将“大数据建模”放入自定义词典中,当用户检索“如何进行大数据建模”时,会将大数据建模这个自定义的关键词增加到推荐结果中。
2 相关搜索结果推荐
将用户检索词的相关搜索词放入文档索引中进行检索,从检索结果排除掉当前页面展示的内容后,展现在相关搜索结果中。
3 相关文档推荐
对于每一篇文档,通过文档向量模型生成文档对应的向量,并将向量作为附加内容与文档一一起存到搜索引擎中,定期计算文档之间的相似度,将最相似的N个文档作为相关文档存到搜索引擎中,当用户浏览特定文档时,将该文档的相关文档列表展示出来。
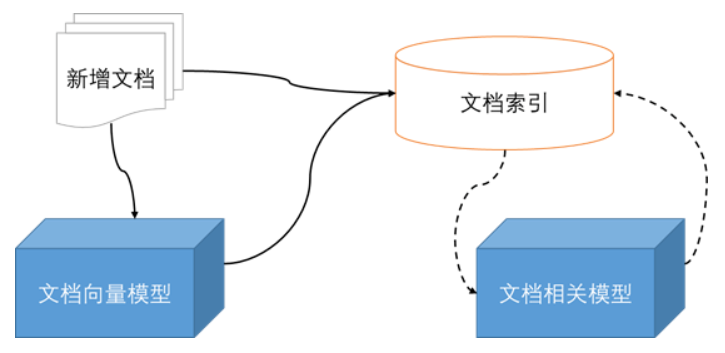
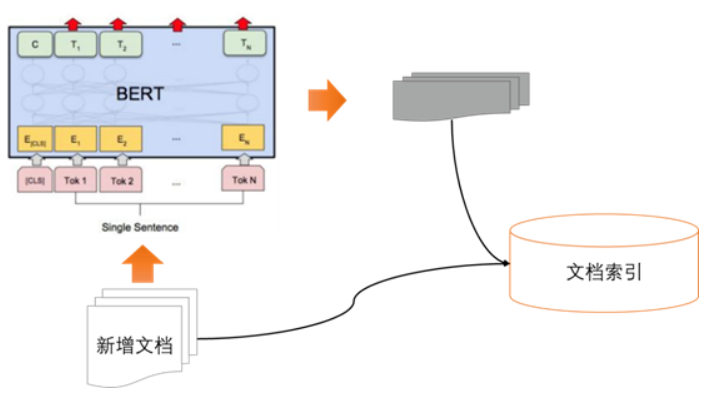
(1)文档向量生成
每次新增文档时,调用文档向量模型,获取每篇文档的向量,将文档及文档向量保存在搜引擎中。
(2)相关文档计算
每天定时当天新增的每一篇文档执行如下操作:
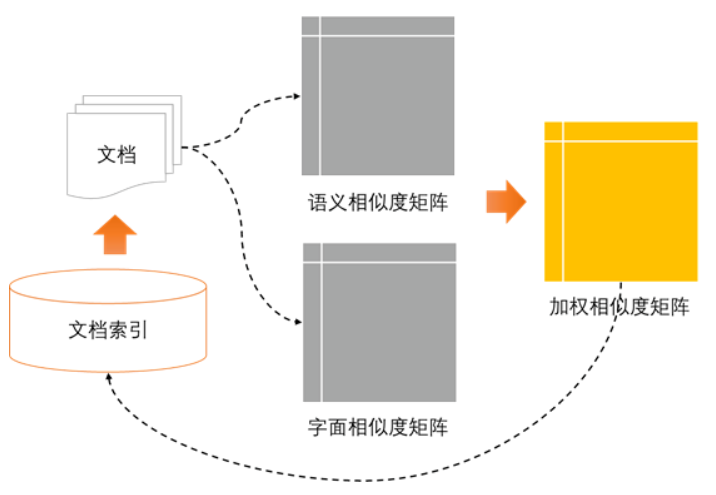
a.在搜索引擎中搜索该文档title,获取前N条得分最高的搜索结果
b.将该文档和搜索得到的N个文档放入相关文档模型中,计算语义相似度和字面相似度,并进行加权得到最终相似度矩阵,将前十个最相关的文档保存到搜索引擎中。
(3)同义词典
项目需要维护领域同义词典,该词典内的词在进行相似度计算时起到权重加大的作用,词典的结构为[["x1","x2"],"x3",["x4","x5"]...],如果元素为列表,表示列表内的元素是同义词。
五、总结
随着集团级企业的数据沉淀越来越多,高效、可靠的数据检索可以大幅度提升数据的利用效率。基于以上技术方案,在构建非结构化文档一体化管理平台的基础上,实现了用户检索时的智能搜索和主动推荐,为公司各级用户提供业务化、融合化、智能化、主动化、个性化的非结构化数据信息资源入口,提高了非结构化数据管理和应用效率,同时提升了业务人员在获取非结构化文件数据时的体验,更好的发挥数据价值。
美林数据多年来已经为高端制造、能源、金融、教育、政务等多个行业的上千家大型企业提供数据治理、数据分析与挖掘等数字化技术服务,持续帮助企业发现数据价值。在数字经济爆发性增长的当下,美林数据将继续发挥技术优势与产品优势,加快大数据、人工智能与实体产业的深度融合,进一步推动数据产业发展,助力企业实现数字化转型。





























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台





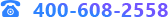




 陕公网安备 61019002000171号
陕公网安备 61019002000171号



