大话数据挖掘之聚类分析(下篇)
2021-02-02 15:59:00
次
人物介绍
许教授:国内数据挖掘专家、某985高校智能信息处理学术带头人
赵总:某电力公司总经理
万总:某超市集团营销副总
李部长:某钢铁集团生产部部长
某985高校管理学院第五届EMBA班的《数据挖掘及其应用》课程上。
国内数据挖掘专家、智能信息处理学术带头人徐教授站在讲台上打开PPT说:“同学们,大家好!今天我们接着上一节课关于聚类分析的内容展开。”
徐教授:“上节课我们讲了k-Means算法和k-Medoids算法的第一个不足。第二个不足就是这两种算法不适用于发现非球状的簇。原因是这类算法使用距离来描述数据之间的相似性,但是,对于非球状数据集,只用距离来描述是不够的。”
“那遇到非球状的聚类问题可怎么办呢?”万总问道。
徐教授答道:“对于这种情况,要用密度来代替相似性设计聚类算法,这就是基于密度的聚类算法即Density-based Method。基于密度的算法从数据对象的分布密度出发,把密度足够大的区域连接起来,从而可以发现任意形状的簇,而且此类算法还能够有效去除噪声。常见的基于密度的聚类算法有DBSCAN,OPTICS,DENCLUE等。”
李部长已经沉默了好长时间,他担心万总又有什么问题影响徐教授的教学进度,赶紧插话道:“徐老师,您刚才说还有一种层次方法,这种聚类方法的思想……”
徐教授:“好,我现在就介绍一下层次方法即Hierarchical Method的基本思想。这种方法按数据分层建立簇,形成一棵以簇为节点的树。如果自底向上进行层次聚集,则称为凝聚的(Aggalomerative)层次聚类;如果自顶向下的进行层次分解,则称为分裂法(Divisive)的层次聚类。”
徐教授润了润嗓子,继续讲道:“凝聚的层次聚类首先将每个对象作为一个簇,然后逐渐合并这些簇形成较大的簇,直到所有的对象都在同一个簇中,或者满足某个终止条件。分裂的层次聚类与之相反,它首先将所有的对象置于一个簇中,然后逐渐划分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终止条件,例如达到了某个希望的簇数目,或两个最近的簇之间的距离超过了一定的阈值。”
李部长一直认真地听着,不断地点头表示他明白了层次聚类的思想。随后,他提问道:“徐老师,层次聚类算法有什么缺点?”
徐教授:“层次方法可以在不同粒度水平上对数据进行探测,而且容易实现相似度量或距离度量。但是,单纯的层次聚类算法的终止条件含糊,而且执行合并或分裂簇的操作不可修正,这很可能导致聚类结果质量很低。另外,由于需要检查和估算大量的对象或簇才能决定簇的合并或分裂,所以这种方法的可扩展性较差。因此,通常在解决实际聚类问题时要把层次方法与其他方法结合起来。层次方法和其他聚类方法的有效结合可以形成多阶段聚类,能够改善聚类质量。这类方法包括BIRCH、CURE、ROCK、Chameleon算法等。”
李部长迫不及待地说:“徐老师,您刚才讲了这么多聚类方法,我发现它们有一个共同的缺点,就是算法无法回答数据对象到底可以聚集为多少类,据说你们研究团队发明了一种视觉聚类算法,很好地解决了这一问题。我们几个人昨天晚上还打赌,我说您今天肯定会讲视觉聚类算法,可都要快下课了,您根本没有提及视觉两字。我们都等不及了,您还是让我们大家欣赏一下视觉聚类的神奇魅力吧!”
说到视觉聚类算法,徐教授脸上露出了会心的微笑。
“好的。视觉聚类算法是基于我们所建立的尺度空间理论建立的,运用这种算法可以对卫星传回的原始图像进行分析,把具有相似属性的事物聚到同一簇中,例如将其用于香港地区地表高精度遥感图像聚类、混杂遥感图像中线状目标如地震带、高速公路、机场跑道等目标识别等。”
李部长听到这里,激动得跳了起来:“徐老师,看来视觉聚类算法有可能用于我们板材表面条纹、夹杂、重皮等质量问题的自动检测,我们试试吧!”
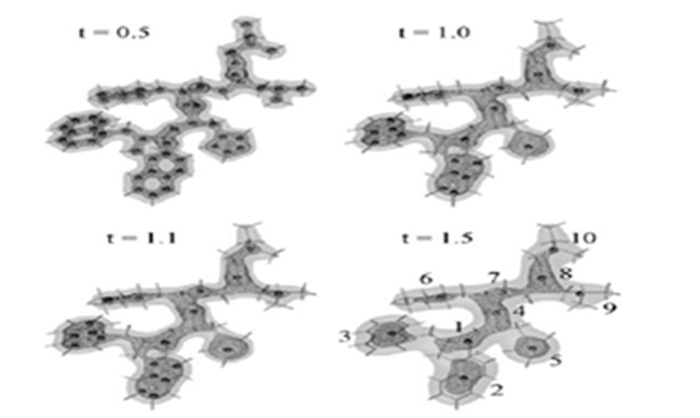
蛋白质分析
赵总:“徐老师,视觉聚类算法可太有用了,真棒!”
徐教授非常高兴:“不谦虚地说,视觉聚类算法确实有其独到之处,其基本思想非常独特:将数据集看作图像,将数据建模问题看作认知问题,通过模拟认知心理学的格式塔原理原理与生物视觉原理解决问题。”
“且慢且慢,什么是格式塔原理?”李部长打断了徐教授的话语。
徐教授翻动了一下PPT:“很简单,格式塔原理就是物体的整体是由局部特征组织在一起的认知原则,请看屏幕。”
“我们将相似率、连续率、闭合率、近邻率和对称率作为聚类的基本原则,模拟人的眼睛由近到远观察景物的过程设计算法进行聚类。随着人由近及远,也就是观察尺度由小变大,所看到的景物的层次会逐渐变化,实际上这就是一个聚类的过程。”徐教授边说边翻了一下PPT。
李部长听得如醉如痴,看着PPT上视觉聚类的示意图,突然,他冒出了一个新的问题:“徐老师,我明白了,在近处,所聚的类会很多,在远处,所聚的类会很少,在很远处,所看到的东西就成为一个类别了。您说,到底聚为多少类最为合适呢?”
徐教授点了点头:“李部长的双核脑袋就是转得快,一下子问道了视觉聚类的关键。随着尺度σ由小变大,聚类的个数在发生变化,但会出现尺度σ在很大范围内变化,而聚类的个数却稳定不变的情况。这个聚类个数存活周期最长,它就是最佳的聚类个数!”
“太妙了,视觉聚类理论通过引进类的生存寿命概念,给出了类的认知定义,解决了聚类有效性问题。数学上严格证明了结构的因果性即类的演化单调性,由此形成了尺度空间聚类的一般性理论框架。”李部长流利地对视觉聚类进行了总结。
徐教授对李部长的话感到纳闷:“李部长,你不是做数据挖掘研究的,不可能给出这么深刻的总结吧!”
李部长笑了笑:“嘿嘿,这是我从网上看到的有人对视觉聚类方法的评价。”
下课铃响了,徐教授边合上电脑边说:“聚类方法我们就简单学习到这儿,下一节可咱们一起讨论数据挖掘非常重要的内容——预测。”
“今天关于关联规则挖掘的内容就介绍到这里。同学们,下节课见!”





























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据资产管理平台
Tempo数据资产管理平台 Tempo主数据管理平台
Tempo主数据管理平台










 陕公网安备 61019002000171号
陕公网安备 61019002000171号



